本文将介绍如何使用docker compose搭建istio。istio号称支持多种平台(不仅仅kubernetes)。然而,官网上非基于kubernetes的教程仿佛不是亲儿子,写得非常随便,不仅缺了一些内容,而且还有坑。本文希望能补实这些内容。我认为在学习istio的过程中,相比于kubernetes,使用docker compose部署更能深刻地理解istio各个组件的用处以及他们的交互关系。在理解了这些后,可以在其他环境,甚至直接在虚拟机上部署istio。当然,生产环境建议使用kubernetes等成熟的容器框架。
本文使用官方的bookinfo示例。通过搭建istio控制平面,部署bookinfo应用,最后配置路由规则,展示istio基本的功能和架构原理。
本文涉及的名词、用到的端口比较多。don't panic.
为了防止不提供原网址的转载,特在这里加上原文链接:
kubectl(kubernetes的客户端)。在微服务架构中,通常除了实现业务功能的微服务外,我们还会部署一系列的基础组件。这些基础组件有些会入侵微服务的代码。比如服务发现需要微服务启动时注册自己,链路跟踪需要在http请求的headers中插入数据,流量控制需要一整套控制流量的逻辑等。这些入侵的代码需要在所有的微服务中保持一致。这导致了开发和管理上的一些难题。
为了解决这个问题,我们再次应用抽象和服务化的思想,将这些需要入侵的功能抽象出来,作为一个独立的服务。这个独立的服务被称为sidecar,这种模式叫sidecar模式。对每个微服务节点,都需要额外部署一个sidecar来负责业务逻辑外的公共功能。所有的出站入站的网络流量都会先经过sidecar进行各种处理或者转发。这样微服务的开发就不需要考虑业务逻辑外的问题。另外所有的sidecar都是一样的,只需要部署的时候使用合适的编排工具即可方便地为所有节点注入sidecar。
sidecar不会产生额外网络成本。sidecar会和微服务节点部署在同一台主机上并且共用相同的虚拟网卡。所以sidecar和微服务节点的通信实际上都只是通过内存拷贝实现的。

图片来自:
sidecar只负责网络通信。还需要有个组件来统一管理所有sidecar的配置。在service mesh中,负责网络通信的部分叫数据平面(data plane),负责配置管理的部分叫控制平面(control plane)。数据平面和控制平面构成了service mesh的基本架构。

图片来自:
istio的数据平面主要由envoy实现,控制平面则主要由istio的pilot组件实现。
如果你使用linux操作系统,需要先配置docker_gateway环境变量。非linux系统不要配。
$ export docker_gateway=172.28.0.1:
到install/consul目录下,使用istio.yaml文件启动控制平面:
根据自己的网络情况(你懂得),可以把
istio.yaml中的镜像gcr.io/google_containers/kube-apiserver-amd64:v1.7.3换成mirrorgooglecontainers/kube-apiserver-amd64:v1.7.3。
$ docker-compose -f istio.yaml up -d
用命令docker-compose -f istio.yaml ps看一下是不是所有组件正常运行。你可能(大概率)会看到pilot的状态是exit 255。使用命令docker-compose -f istio.yaml logs | grep pilot查看日志发现,pilot启动时访问istio-apiserver失败。这是因为docker compose是同时启动所有容器的,在pilot启动时,istio-apiserver也是处于启动状态,所以访问istio-apiserver就失败了。
等istio-apiserver启动完成后,重新运行启动命令就能成功启动pilot了。你也可以写一个脚本来自动跑两次命令:
docker-compose -f istio.yaml up -d # 有些依赖别人的第一次启动会挂 sec=10 # 根据你的机器性能这个时间可以修改 echo "wait $sec seconds..." sleep $sec docker-compose -f istio.yaml up -d docker-compose -f istio.yaml ps
配置kubectl,让kubectl使用我们刚刚部署的istio-apiserver作为服务端。我们后面会使用kubectl来执行配置管理的操作。
$ kubectl config set-context istio --cluster=istio $ kubectl config set-cluster istio --server=http://localhost:8080 $ kubectl config use-context istio
部署完成后,使用地址localhost:8500可以访问consul,使用地址localhost:9411可以访问zipkin。
在下一步之前,我们先来看一下控制平面都由哪些组件组成。下面是istio.yaml文件的内容:
# generated file. use with docker-compose and consul
# to update, modify files in install/consul/templates and run install/updateversion.sh
version: '2'
services:
etcd:
image: quay.io/coreos/etcd:latest
networks:
istiomesh:
aliases:
- etcd
ports:
- "4001:4001"
- "2380:2380"
- "2379:2379"
environment:
- service_ignore=1
command: ["/usr/local/bin/etcd", "-advertise-client-urls=http://0.0.0.0:2379", "-listen-client-urls=http://0.0.0.0:2379"]
istio-apiserver:
# 如果这个镜像下载不了的话,可以换成下面的地址:
# image: mirrorgooglecontainers/kube-apiserver-amd64:v1.7.3
image: gcr.io/google_containers/kube-apiserver-amd64:v1.7.3
networks:
istiomesh:
ipv4_address: 172.28.0.13
aliases:
- apiserver
ports:
- "8080:8080"
privileged: true
environment:
- service_ignore=1
command: ["kube-apiserver", "--etcd-servers", "http://etcd:2379", "--service-cluster-ip-range", "10.99.0.0/16", "--insecure-port", "8080", "-v", "2", "--insecure-bind-address", "0.0.0.0"]
consul:
image: consul:1.3.0
networks:
istiomesh:
aliases:
- consul
ports:
- "8500:8500"
- "${docker_gateway}53:8600/udp"
- "8400:8400"
- "8502:8502"
environment:
- service_ignore=1
- dns_resolves=consul
- dns_port=8600
- consul_data_dir=/consul/data
- consul_config_dir=/consul/config
entrypoint:
- "docker-entrypoint.sh"
command: ["agent", "-bootstrap", "-server", "-ui",
"-grpc-port", "8502"
]
volumes:
- ./consul_config:/consul/config
registrator:
image: gliderlabs/registrator:latest
networks:
istiomesh:
volumes:
- /var/run/docker.sock:/tmp/docker.sock
command: ["-internal", "-retry-attempts=-1", "consul://consul:8500"]
pilot:
image: docker.io/istio/pilot:1.1.0
networks:
istiomesh:
aliases:
- istio-pilot
expose:
- "15003"
- "15005"
- "15007"
ports:
- "8081:15007"
command: ["discovery",
"--httpaddr", ":15007",
"--registries", "consul",
"--consulserverurl", "http://consul:8500",
"--kubeconfig", "/etc/istio/config/kubeconfig",
"--securegrpcaddr", "",
]
volumes:
- ./kubeconfig:/etc/istio/config/kubeconfig
zipkin:
image: docker.io/openzipkin/zipkin:2.7
networks:
istiomesh:
aliases:
- zipkin
ports:
- "9411:9411"
networks:
istiomesh:
ipam:
driver: default
config:
- subnet: 172.28.0.0/16
gateway: 172.28.0.1
控制平面部署了这几个组件(使用istio.yaml里写的名称):
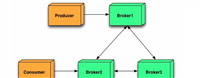
etcd:分布式key-value存储。istio的配置信息存在这里。istio-apiserver:实际上是一个kube-apiserver,提供了kubernetes格式数据的读写接口。consul:服务发现。registrator:监听docker服务进程,自动将容器注册到consul。pilot:从consul和istio-apiserver收集主机信息与配置数据,并下发到所有的sidecar。zipkin:链路跟踪组件。与其他组件的关系相对独立。这些组件间的关系如下图:

控制平面主要实现了以下两个功能:
etcd和kube-apiserver的组合可以看作是一个对象存储系统,它提供了读写接口和变更事件,并且可以直接使用kubectl作为客户端方便地进行操作。istio直接使用这个组合作为控制平面的持久化层,节省了重复开发的麻烦,另外也兼容了kubernetes容器框架。pilot容器中实际执行的是pilot-discovery(发现服务)。它从consul收集各个主机的域名和ip的对应关系,从istio-apiserver获取流量控制配置,然后按照envoy的xds api规范生成envoy配置,下发到所有sidecar。接下来我们开始部署微服务。这里我们使用istio提供的例子,一个bookinfo应用。
bookinfo 应用分为四个单独的微服务:
productpage:productpage微服务会调用details和reviews两个微服务,用来生成页面。details:这个微服务包含了书籍的信息。reviews:这个微服务包含了书籍相关的评论。它还会调用ratings微服务。ratings:ratings微服务中包含了由书籍评价组成的评级信息。reviews微服务有3个版本:
ratings服务。ratings服务,并使用1到5个黑色星形图标来显示评分信息。ratings服务,并使用1到5个红色星形图标来显示评分信息。bookinfo应用的架构如下图所示:

图片来自:bookinfo应用
首先,我们切换到这个示例的目录samples/bookinfo/platform/consul下。
使用bookinfo.yaml文件启动所有微服务:
$ docker-compose -f bookinfo.yaml up -d
这里只启动了微服务,还需使用bookinfo.sidecar.yaml文件启动所有sidecar:
$ docker-compose -f bookinfo.sidecars.yaml up -d
部署完毕。但是当我们访问时……
bookinfo暴露到外面的端口是9081,使用地址localhost:9081/productpage访问productpage页面。
emmm……出错了:

本来应该显示reviews的部分报错了,而details还是正常的。经过一番排查,我们发现,在所有微服务的容器上,不管你访问的是productpage、details、reviews还是ratings,网络请求都会跑到details。
你的情况不一定是
details,也有可能所有流量都跑到另外的某个服务。这是随机的。
# 到reviews查reviews,返回404
$ docker exec -it consul_ratings-v1_1 curl reviews.service.consul:9080/reviews/0
<!doctype html public "-//w3c//dtd html 4.0//en">
<html>
<head><title>not found</title></head>
<body>
<h1>not found</h1>
`/reviews/0' not found.
<hr>
<address>
webrick/1.3.1 (ruby/2.3.8/2018-10-18) at
reviews.service.consul:9080
</address>
</body>
</html>
# 到reviews查details,反倒能查出数据,诡异的路由……
$ docker exec -it consul_ratings-v1_1 curl reviews.service.consul:9080/details/0
{"id":0,"author":"william shakespeare","year":1595,"type":"paperback","pages":200,"publisher":"publishera","language":"english","isbn-10":"1234567890","isbn-13":"123-1234567890"}
不用怀疑部署的时候哪里操作失误了,就是官方的部署文件有坑……
要解决这个问题,我们来看看sidecar的原理。
首先看看两个部署用的yaml文件都做了什么。由于每个微服务的部署都大同小异,这里只贴出productpage相关的内容。
bookinfo.yaml:
version: '2'
services:
……
productpage-v1:
image: istio/examples-bookinfo-productpage-v1:1.10.1
networks:
istiomesh:
ipv4_address: 172.28.0.14
dns:
- 172.28.0.1
- 8.8.8.8
dns_search:
- service.consul
environment:
- service_name=productpage
- service_tags=version|v1
- service_protocol=http
ports:
- "9081:9080"
expose:
- "9080"
……
dns_search: - search.consul。docker compose部署的这套样例对短服务主机名的解析可能会有问题,所以这里需要加个后缀。environment环境变量的几个设置。registrator会以这些环境变量为配置将服务注册到consul。service_name是注册的服务名,service_tags是注册服务的servicetags,而service_protocol=http则会将protocol: http加入到servicemeta。bookinfo.sidecar.yaml:
version: '2'
services:
……
productpage-v1-init:
image: docker.io/istio/proxy_init:0.7.1
cap_add:
- net_admin
network_mode: "container:consul_productpage-v1_1"
command:
- -p
- "15001"
- -u
- "1337"
productpage-v1-sidecar:
image: docker.io/istio/proxy_debug:1.1.0
network_mode: "container:consul_productpage-v1_1"
entrypoint:
- su
- istio-proxy
- -c
- "/usr/local/bin/pilot-agent proxy --serviceregistry consul --servicecluster productpage-v1 --zipkinaddress zipkin:9411 --configpath /var/lib/istio >/tmp/envoy.log"
……
proxy_init,这个容器执行完就退出了;另一个是实际的sidecar程序proxy_debug。network_mode,值为container:consul_productpage-v1_1。这是docker的容器网络模式,意思是这两个容器和productpage-v1共用同一个虚拟网卡,即它们在相同网络栈上。proxy_initsidecar的网络代理一般是将一个端口转发到另一个端口。所以微服务使用的端口就必须和对外暴露的端口不一样,这样一来sidecar就不够透明。
为了使sidecar变得透明,以istio使用proxy_init设置了iptables的转发规则(proxy_init、proxy_debug和productpage-v1在相同的网络栈上,所以这个配置对这三个容器都生效)。添加的规则为:
比如productpage服务使用的9080端口,当其他服务通过9080端口访问productpage是,请求会先被iptables转发到15001端口,envoy再根据路由规则转发到9080端口。这样访问9080的流量实际上都在15001绕了一圈,但是对外部来说,这个过程是透明的。

proxy_debugproxy_debug有两个进程:pilot-agent和envoy。proxy_debug启动时,会先启动pilot-agent。pilot-agent做的事很简单,它生成了envoy的初始配置文件/var/lib/istio/envoy-rev0.json,然后启动envoy。后面的事就都交给envoy了。
使用下面命令导出初始配置文件:
$ docker exec -it consul_productpage-v1-sidecar_1 cat /var/lib/istio/envoy-rev0.json > envoy-rev0.json
使用你心爱的编辑器打开初始配置文件,可以看到有这么一段:
……
"name": "xds-grpc",
"type": "strict_dns",
"connect_timeout": "10s",
"lb_policy": "round_robin",
"hosts": [
{
"socket_address": {"address": "istio-pilot", "port_value": 15010}
}
],
……
这一段的意思是envoy会连接到pilot(控制平面的组件,忘记了请往上翻翻)的15010端口。这俩将按照xds的api规范,使用grpc协议实时同步配置数据。
xds是envoy约定的一系列发现服务(discovery service)的统称。如cds(cluster discovery service),eds(endpoint discovery service),rds(route discovery service)等。envoy动态配置需要从实现了xds规范的接口(比如这里的
pilot-discovery)获取配置数据。
总结一下,envoy配置初始化流程为:

图片来自:
那么说envoy实际使用的路由配置并不在初始配置文件中,而是pilot生成并推送过来的。如何查看envoy的当前配置呢?还好envoy暴露了一个管理端口15000:
$ docker exec -it consul_productpage-v1-sidecar_1 curl localhost:15000/help admin commands are: /: admin home page /certs: print certs on machine /clusters: upstream cluster status /config_dump: dump current envoy configs (experimental) /contention: dump current envoy mutex contention stats (if enabled) /cpuprofiler: enable/disable the cpu profiler /healthcheck/fail: cause the server to fail health checks /healthcheck/ok: cause the server to pass health checks /help: print out list of admin commands /hot_restart_version: print the hot restart compatibility version /listeners: print listener addresses /logging: query/change logging levels /memory: print current allocation/heap usage /quitquitquit: exit the server /reset_counters: reset all counters to zero /runtime: print runtime values /runtime_modify: modify runtime values /server_info: print server version/status information /stats: print server stats /stats/prometheus: print server stats in prometheus format
我们可以通过/config_dump接口导出envoy的当前配置:
$ docker exec -it consul_productpage-v1-sidecar_1 curl localhost:15000/config_dump > envoy.json
打开这个配置,看到这么一段:
……
"listener": {
"name": "0.0.0.0_9080",
"address": {
"socket_address": {
"address": "0.0.0.0",
"port_value": 9080
}
},
"filter_chains": [
{
"filters": [
{
"name": "envoy.tcp_proxy",
"typed_config": {
"@type": "type.googleapis.com/envoy.config.filter.network.tcp_proxy.v2.tcpproxy",
"stat_prefix": "outbound|9080||details.service.consul",
"cluster": "outbound|9080||details.service.consul",
……
猜一下也能知道,这一段的意思是,访问目标地址9080端口的出站流量,都会被路由到details。太坑了!!!
从上面原理分析可知,这个问题的根源应该在于pilot给envoy生成的配置不正确。
查看pilot得知,pilot在生成配置时,用一个map保存listener信息。这个map的key为<ip>:<port>。如果服务注册的时候,没有指明端口<port>上的协议的话,默认认为tcp协议。pilot会将这个listener和路由写入到这个map,并拒绝其他相同地址端口再来监听。于是只有第一个注册的服务的路由会生效,所有流量都会走到那个服务。如果这个端口有指定使用http协议的话,pilot-discovery这里生成的是一个rds的监听,这个rds则根据域名路由到正确的地址。
简单说就是所有微服务在注册到consul时应该在servicemeta中说明自己9080端口的协议是http。
等等,前面的bookinfo.yaml配置里,有指定9080端口的协议是了呀。我们访问一下consul的接口看下servicemeta是写入了没有:

果然没有……看来registrator注册的时候出了岔子。网上搜了下,确实有issue提到了这个问题:。istio.yaml中使用的latest版本的registrator不支持写入consul的servicemeta。应该改为master版本。
修改一下istio.yaml配置。按照部署倒叙关闭sidecar、微服务,重新启动控制平面,等registrator启动完毕后,重新部署微服务和sidecar。
# /samples/bookinfo/platform/consul $ docker-compose -f bookinfo.sidecars.yaml down $ docker-compose -f bookinfo.yaml down # /install/consul $ docker-compose -f istio.yaml up -d # /samples/bookinfo/platform/consul $ docker-compose -f bookinfo.yaml up -d $ docker-compose -f bookinfo.sidecars.yaml up -d
再访问consul的接口试试,有了(没有的话可能是registrator没启动好导致没注册到consul,再新部署下微服务和sidecar):

再访问页面,ok了。目前没有配置路由规则,reviews的版本是随机的。多刷新几次页面,可以看到打星在“没有星星”、“黑色星星”和“红色星星”三种效果间随机切换。
使用地址http://localhost:9411能访问zipkin链路跟踪系统,查看微服务请求链路调用情况。
我们来看看正确的配置是什么内容。再取出envoy的配置,0.0.0.0_9080的listener内容变为:
……
"listener": {
"name": "0.0.0.0_9080",
"address": {
"socket_address": {
"address": "0.0.0.0",
"port_value": 9080
}
},
"filter_chains": [
{
"filters": [
{
"name": "envoy.http_connection_manager",
"typed_config": {
"@type": "type.googleapis.com/envoy.config.filter.network.http_connection_manager.v2.httpconnectionmanager",
"stat_prefix": "0.0.0.0_9080",
"rds": {
"config_source": {
"ads": {}
},
"route_config_name": "9080"
},
……
9080端口的出站路由规则由一个名称为"9080"的route_config定义。找一下这个route_config:
……
"route_config": {
"name": "9080",
"virtual_hosts": [
{
"name": "details.service.consul:9080",
"domains": [
"details.service.consul",
"details.service.consul:9080",
"details",
"details:9080",
"details.service",
"details.service:9080"
],
"routes": [
{
"match": {
"prefix": "/"
},
"route": {
"cluster": "outbound|9080|v1|details.service.consul",
……
},
……
}
]
},
{
"name": "productpage.service.consul:9080",
"domains": [
"productpage.service.consul",
"productpage.service.consul:9080",
"productpage",
"productpage:9080",
"productpage.service",
"productpage.service:9080"
],
"routes": [
{
"match": {
"prefix": "/"
},
"route": {
"cluster": "outbound|9080|v1|productpage.service.consul",
……
},
……
}
]
},
……
由于内容太长,这里只贴details和productpage的关键内容。可以看到,9080端口的出站流量会根据目标地址的域名正确地转发到对应的微服务。
注意:本节工作目录为/samples/bookinfo/platform/consul。
最后我们尝试一下istio的路由控制能力。在配置路由规则之前,我们要先使用destinationrule定义各个微服务的版本:
$ kubectl apply -f destination-rule-all.yaml
destinationrule:destinationrule定义了每个服务下按照某种策略分割的子集。在本例子中按照版本来分子集,
reviews分为v1、v2、v3三个版本的子集,其他微服务都只有v1一个子集。
使用命令kubectl get destinationrules -o yaml可以查看已配置的destinationrule。
接下来我们使用virtualservice来配置路由规则。virtual-service-all-v1.yaml配置会让所有微服务的流量都路由到v1版本。
$ kubectl apply -f virtual-service-all-v1.yaml
virtualservice:定义路由规则,按照这个规则决定每次请求服务应该将流量转发到哪个子集。
使用命令kubectl get virtualservices -o yaml可以查看已配置的virtualservice。
再刷新页面,现在不管刷新多少次,reviews都会使用v1版本,也就是页面不会显示星星。
下面我们试一下基于用户身份的路由规则。配置文件virtual-service-reviews-test-v2.yaml配置了reviews的路由,让用户jason的流量路由到v2版本,其他情况路由到v1版本。
$ kubectl apply -f virtual-service-reviews-test-v2.yaml
执行命令后刷新页面,可以看到reviews都使用的v1版本,页面不会显示星星。点击右上角的sign in按钮,以jason的身份登录(密码随便),可以看到reviews切换到v2版本了,页面显示了黑色星星。
查看virtual-service-reviews-test-v2.yaml文件内容可以看到,基于身份的路由是按照匹配http的headers实现的。当http的headers有end-user: jason的内容时路由到v2版本,否则路由到v1版本。
apiversion: networking.istio.io/v1alpha3
kind: virtualservice
metadata:
name: reviews
spec:
hosts:
- reviews.service.consul
http:
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: reviews.service.consul
subset: v2
- route:
- destination:
host: reviews.service.consul
subset: v1
istio.yaml引用的registrator的latest版本不支持consul的servicemeta。要改为master版本。istio.yaml后,因为启动时pilot连不上istio-apiserver,pilot会失败退出。等待istio-apiserver启动完毕后再跑一次istio.yaml。kubectl的context,让kubectl使用istio-apiserver提供的kubernetes api接口。bookinfo.yaml启动各个微服务后,还要运行bookinfo.sidecar.yaml以初始化和启动sidecar。
如对本文有疑问, 点击进行留言回复!!


14、Ribbon整合断路器监控Hystrix Dashboard

网友评论