店名打分,通天鸟,上师大主页
昨天我们学习了支持向量机基本概念,重申数学推导原理的重要性并向大家介绍了一篇非常不错的文章。今天,我们使用scikit-learn中的svc分类器实现svm。我们将在day16使用kernel-trick实现svm。
import numpy as np import matplotlib.pyplot as plt import pandas as pd
数据集依然是social_network_ads,下载链接:
https://pan.baidu.com/s/1cpbt2daf2nraomhbk5-_pq
dataset = pd.read_csv('social_network_ads.csv') x = dataset.iloc[:, [2, 3]].values y = dataset.iloc[:, 4].values
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 0)
from sklearn.preprocessing import standardscaler sc = standardscaler() x_train = sc.fit_transform(x_train) x_test = sc.fit_transform(x_test)
from sklearn.svm import svc classifier = svc(kernel = 'linear', random_state = 0) classifier.fit(x_train, y_train)
y_pred = classifier.predict(x_test)
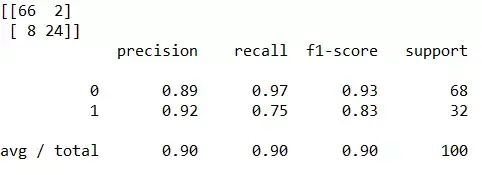
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred)
from matplotlib.colors import listedcolormap x_set, y_set = x_train, y_train x1, x2 = np.meshgrid(np.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step = 0.01), np.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01)) plt.contourf(x1, x2, classifier.predict(np.array([x1.ravel(), x2.ravel()]).t).reshape(x1.shape), alpha = 0.75, cmap = listedcolormap(('red', 'green'))) plt.xlim(x1.min(), x1.max()) plt.ylim(x2.min(), x2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1], c = listedcolormap(('red', 'green'))(i), label = j) plt.title('svm (training set)') plt.xlabel('age') plt.ylabel('estimated salary') plt.legend() plt.show()
from matplotlib.colors import listedcolormap x_set, y_set = x_test, y_test x1, x2 = np.meshgrid(np.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step = 0.01), np.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01)) plt.contourf(x1, x2, classifier.predict(np.array([x1.ravel(), x2.ravel()]).t).reshape(x1.shape), alpha = 0.75, cmap = listedcolormap(('red', 'green'))) plt.xlim(x1.min(), x1.max()) plt.ylim(x2.min(), x2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1], c = listedcolormap(('red', 'green'))(i), label = j) plt.title('svm (test set)') plt.xlabel('age') plt.ylabel('estimated salary') plt.legend() plt.show()
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!!
点击进行留言回复



网友评论