m美女裤裆凸起照片,上杭征婚,拳皇大战dnf0.95

Spark Streaming处于Spark生态技术栈中,可以和Spark Core和Spark SQL无缝整合;而Storm相对来说比较单一;
(一)概述
Spark StreamingSpark Streaming是Spark的核心API的一个扩展,可以实现高吞吐量、具有容错机制的实时流数据的处理。支持从多种数据源获取数据,包括kafka、Flume、Twitter、ZeroMQ以及TCP等,从数据获取之后,可以使用诸如map、reduce、join、window等高级函数进行复杂算法处理。最后还可以将处理结果存储到文件系统,数据库;还可以使用Spark的其他子框架,如图计算等,对流数据进行处理。
Spark Streaming在内部的处理机制是,就收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后处理这些批数据,最终得到处理后的一批结果数据。对应的批数据(batch data),在Spark内核对应一个RDD实例,因此,对流数据DStream可以看成是一组RDDs。
执行流程(Receiver模式):

提高并行度:receiver task会每隔200ms block.interval将接受来的数据分装到block中,调整block.interval的值;
启用多个receiver进程来并行接受数据;
对于Direct模式提高并行度的方式只需增加kafka partition的数量;Director模式,消费者偏移量由spark自己管理,存在checkpoint目录中
Storm 
storm采用Master/Slave体系结构
nimbus:该进程运行在集群的主节点上,负责任务的指派和分发
supervisor:运行在集群的从节点上,负责执行任务的具体部分
zookeeper:帮助主从做到解耦,存储集群资源元数据,当storm把元数据信息都存到zk中后,那storm自己就做到了无状态,提交Topology应用的时候才会用到nimbus;
worker:运行处理具体组件逻辑进程,worker之间通过netty传送数据
task:worker中每个spout/bolt的线程称为一个task,同一个spout/bolt的task可能会共享一个物理进程,该线程为executor
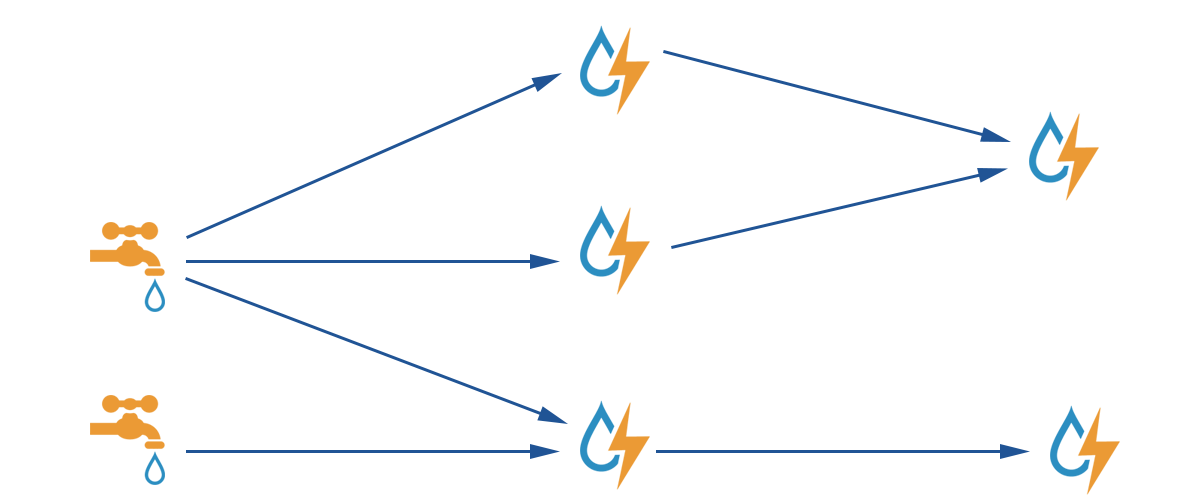
以上由spout和bolt组成的图叫做topologies,上层的spout或者bolt向下层的Bolt来发射数据的时候,默认情况下都是default stream
storm常用的分发策略一共有5种,最常用的是Shuffle grouping和Fields grouping
storm中的ack机制:说白了就是storm通过Acker组件去数数,数Tuple tree里面的Tuple是否都已经确认过,每个Tuple Tree对应一个msgId
提高并行度:
增加worker数量;增加Executor数量;设置task数量,默认一个线程里面跑一个task
Storm实现可靠的消息保障机制:

Tuple 的完全处理需要 Spout、Bolt 以及 Acker(Storm 中用来记录某棵 Tuple 树是否被完全处理的节点)协同完成,如上图所示。从 Spout 发送 Tuple 到下游,并把相应信息通知给 Acker,整棵 Tuple 树中某个 Tuple 被成功处理了都会通知 Acker,待整棵 Tuple 树都被处理完成之后,Acker 将成功处理信息返回给 Spout;如果某个 Tuple 处理失败,或者超时,Acker 将会给 Spout 发送一个处理失败的消息,Spout 根据 Acker 的返回信息以及用户对消息保证机制的选择判断是否需要进行消息重传。
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复

去 HBase,Kylin on Parquet 性能表现如何?

如何找到Hive提交的SQL相对应的Yarn程序的applicationId
如何在 HBase Shell 命令行正常查看十六进制编码的中文?哈哈~


HBase Filter 过滤器之 Comparator 原理及源码学习

安装 Hadoop 2.9.1 on Windows 10 64 bit (最全步骤整理)
网友评论