随着amd锐龙的横空出世,电脑cpu进入了多核震慑的时代。
同一系列的产品,核心翻倍已经司空见惯,有爆料显示intel下一代cpu的i3将会配备4核8线程——这样的cpu,三年前它的名字叫i7。
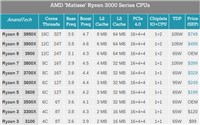
而在高端系列中,核战更是令人心惊胆战,在售的amd锐龙3900x的12核24线程已经足以令人倒吸一口凉气,而即将上市的3950x更是配备了16核24线程,数框框爱好者们纷纷表示把持不住,高呼yes根本停不下来。
然而多核cpu打游戏一定会更快吗?不一定。排除频率、架构ipc的差异,某些情况下多核cpu打游戏甚至会更慢——例如在某些情况下,amd的12核新品3900x,某些游戏中要比8核的3700x更慢。

有测试显示,核心更多、频率更高的3900x在某些情况游戏表现不如3700x
要知道从规格来看,3900x全面压倒3700x,且不说核心多了四个,连频率也更高(3.8/4.6ghz vs 3.6/4.4ghz),3级缓存也翻了倍(64mbvs32mb),那为什么会出现多核玩游戏更慢的情况?
今天就从这个现象出发,谈谈cpu和游戏优化的那点事吧。
游戏的多核优化有多难?
我们就先从游戏对多核心的优化谈起吧。谈游戏的优化,就绕不开对多核的支持。什么游戏对多核优化好、什么游戏只能一核有难、多核围观,一直是玩家们津津乐道的话题。
为什么游戏在对多核心的优化上会出问题,而视频压缩等应用就能充分利用多核心?这和游戏的运行机制有关。
为何游戏喜欢用单核心?
视频压缩这类任务可以轻易做到并行计算,例如一个线程压缩某个片段,另一个线程压缩另一个片段,多核一起运作,最后压缩完成所有片段,完整视频也就压缩完成了。
而游戏的运行一般都是线性的,某一步的运算往往会和上一步息息相关,很难充分利用多个线程。
例如在fps游戏中,某个玩家被击中产生伤害,那么这个伤害结果和子弹运行轨迹有关,需要先计算出子弹轨迹然后才能计算出伤害,这只能在一条线程中先后完成,无法通过多线程同时计算子弹轨迹和伤害。
游戏想要充分利用多核,需要巧妙地将计算任务拆分成为多线程,例如不同的线程负责物理碰撞、ai行为等,技术门槛比较高,也得下更多功夫。基于此,目前仍有大量游戏未能充分利用cpu的所有核心。
支持多核心一定优化好吗?
随着时代的发展,越来越多游戏愿意在多线程优化上做出努力。
例如前几年,我们经常可以看到“i3默秒全”的情况,而现在的游戏大作已经将门槛提升至4核,双核i3已经难堪大任。
但尽管如此,仍会出现12核3900x表现不如8核3700x的情况,这又是为何?
出现这种情况,主要在于cpu核心调度不合理。锐龙的架构比较特殊,每4个核心封装成为一个ccx,每两个ccx封装为一个ccd,核心和核心之间的通讯,可以跨ccx,乃至跨ccd,而无论是ccx还是ccd之间通信,都存在延迟。
换言之,如果一个程序能够调用多个核心,会出现以下几种情况。
1、调用的多核心处于同一ccx内,延迟最小;
2、调用的多核心跨ccx,但处于同一ccd内,有所延迟;
3、调用的多核心跨ccx、跨ccd,延迟最大
例如一个游戏可以调用4个核心,最理想的情况自然是调用同一ccx内的4核,这样能获得最好的性能。
但实际上,代码对多核心的调用不一定这么智能,很有可能不能辨认出哪些核心位于同一ccx上。于是,游戏可能会调用位于不同ccx、ccd的多个核心,产生的额外延迟导致性能有所损失。
知道了这些,就可以解释为什么有时候3900x的游戏表现有时候还要低于3700x了。3900x封装了两个ccd,每个ccd内有两个ccx,每个ccx有4核心,原生共4x2x2=16核心,屏蔽了4核心后得12核。
而3700x则只有一个ccd,内含两个ccx,共4x2=8核。可见,3900x比3700x多了一个ccd,多了一种可能产生额外延迟的情况,如果游戏不能发挥出3900x的多核心优势,那么3900x表现略逊于3700x也就在情理之中了。

因此,即使游戏对多核进行了优化,但在核心调度方面,也需要另外下更多功夫,才能取得最佳性能。
很高兴的是,微软已经意识到了相关问题,在windows 10 1903中做出了优化,系统会优先调度处于同一ccx内的核心,避免跨ccx造成的延迟。
如果你想要更好地发挥amd ryzen处理器的性能,升级到windows 10 1903还是很有必要的。
2cpu单核性能真的在挤牙膏?cpu单核性能真的在挤牙膏?有人认为,目前cpu已经很难从频率上做性能突破,架构亦难以进一步提升效率,堆核是性能进步的唯一之道。
有的朋友从intel的“挤牙膏”中论证这一观点,认为cpu的同频性能已经多年止步不前,而amd的zen2架构尽管效率相对于前代大幅提升,但也只是追上竞争对手的水平而已。
用数年前的4核cpu和现在的4核cpu玩游戏,体验似乎并没有什么不同,也是一个有力的佐证。但事实是否如此?
实际上,这种观点是片面的。之所以数年前的cpu在某些测试、某些游戏中表现尚可,是因为这些测试、游戏并没有针对新cpu的指令集作出优化。
近年来,新款cpu的一大价值在于增加了avx、avx2、tsx等指令集。
如果代码调用了相应指令集,能更高效地利用fma这样的浮点加乘混合单元,减少cpu流水线的闲置,性能表现可以获得可观的提升。
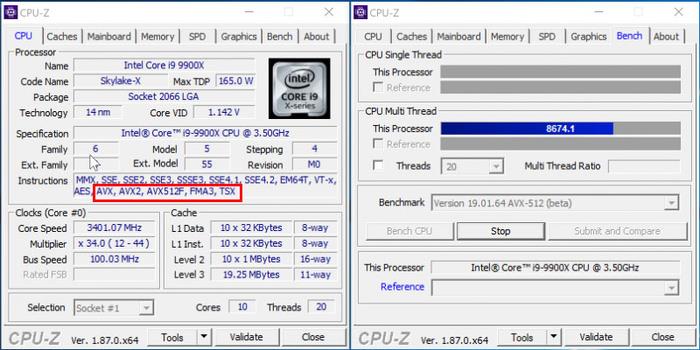
这些都可是近十年间陆续增加的指令集,不是说没有堆核就是挤牙膏
以著名的渲染软件cinebench为例,这是diy玩家都相当熟悉的cpu测试工具。
最新版的cinebench r20对比旧版的cinebench r15,一大改进就是加入了avx指令集的支持。
在cpu对avx指令集有较好支持的情况下,同样的渲染项目,在cinebench r20中跑,速度甚至要比cinebench r15快一倍以上!新型指令集对性能的提升之巨,由此可见一斑。

zen2的单核性能进步如此大,很大程度上是因为avx2性能大幅提高
支持avx或更新的指令集已经在渲染、视频压缩、科学计算等专业领域中渐渐成为常态,著名的linux发行版fedora 32甚至计划不支持没有avx指令集的cpu。
然而,仍有大量游戏未跟进avx等新指令集,只支持老的sse,新cpu跑这些游戏自然和旧款cpu没有太大区别。在指令集支持方面,游戏对cpu仍缺乏应有的优化。
著名的游戏性能测试组件3dmark已经意识到了这点。在新的time spy extreme测试项目当中,加入了avx、avx2乃至avx512指令集支持,调用avx512指令集跑分,成绩对比sse3跑出来的分数高了一倍有余。
avx等新指令集在实际游戏中意义也变得越来越重大,例如《刺客信条:奥德赛》甚至不支持没有avx指令集的cpu(因为太激进,后来不得不重新兼容老cpu)。
又例如某些使用了d加密的游戏需要fma3指令集才能正确解密运行,早年的“神u”e1230 v2只能干瞪眼;如果你是ps3模拟器玩家,也有切身体会过tsx指令集下性能的飞跃。

总体而言,大部分游戏在指令集方面的优化做得依然不够,在缺乏指令集优化的情况下,旧cpu和新cpu的游戏表现拉不出太大差距。
但支持新指令集是游戏对cpu优化中无法规避的环节,活用新指令集才能彰显新款cpu应有的价值,希望有更多游戏对新的cpu指令集作出优化吧。
后话
无论是增加cpu核心多线程,还是使用新型指令集提升simd性能,都可以大大增强cpu的性能。
就消费市场而言,amd似乎更多地走了多核路线,而intel则致力于推行新指令集。但无论是哪种发展方向,都需要相应的软件对此作出优化,才能发挥出cpu应有的性能。
现在早已经不是不改一行代码就能发挥出新cpu的全部性能的时代,多核心和先进指令集,限于匮乏游戏支持的现状,都不得不沦为“战未来”。
cpu并没有在“挤牙膏”,游戏对cpu的优化也远未到尽头,希望未来我们能看到更多能发挥出cpu真正功力的游戏吧。

如对本文有疑问, 点击进行留言回复!!

2年升级一次 Intel:10nm、7nm及5nm工艺开发不会削减投资



AMD推土机FX-8350超频至8.1GHz!却打不过3.6GHz锐龙
网友评论