v3.9d.w3x,玻璃钢垃圾桶厂家,造梦西游3天兵
首先我们在讲rabbitMQ之前我们要说一下python里的queue:二者干的事情是一样的,都是队列,用于传递消息
在python的queue中有两个一个是线程queue,一个是进程queue(multiprocessing中的queue)。线程queue不能够跨进程,用于多个线程之间进行数据同步交互;进程queue只是用于父进程与子进程,或者同属于同意父进程下的多个子进程 进行交互。也就是说如果是两个完全独立的程序,即使是python程序,也依然不能够用这个进程queue来通信。那如果我们有两个独立的python程序,分属于两个进程,或者是python和其他语言
安装:windows下
安装pika:
之前安装过了pip,直接打开cmd,运行pip install pika
安装完毕之后,实现一个最简单的队列通信:

producer:
1 import pika
2
3 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
4 #声明一个管道
5 channel = connection.channel()
6
7 #声明queue
8 channel.queue_declare(queue = 'hello')
9 #routing_key是queue的名字
10 channel.basic_publish(exchange='',
11 routing_key='hello',#queue的名字
12 body='Hello World!',
13 )
14 print("[x] Send 'Hello World!'")
15 connection.close()
先建立一个基本的socket,然后建立一个管道,在管道中发消息,然后声明一个queue,起个队列的名字,之后真正的发消息(basic_publish)
consumer:
1 import pika
2 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
3 channel = connection.channel()
4
5 channel.queue_declare(queue='hello')
6
7
8 def callback(ch, method, properties, body):#回调函数
9 print("---->",ch,method,properties)
10 print(" [x] Received %r" % body)
11
12 channel.basic_consume(callback,#如果收到消息,就调用callback来处理消息
13 queue='hello',
14 no_ack=True
15 )
16
17 print(' [*] Waiting for messages. To exit press CTRL+C')
18 channel.start_consuming()
start_consuming()只要一启动就一直运行下去,他不止收一条,永远在这里卡住。
在上面不管是produce还是consume,里面都声明了一个queue,这个是为什么呢?因为我们不知道是消费者先开始运行还是生产者先运行,这样如果没有声明的话就会报错。
下面我们来看一下一对多,即一个生产者对应多个消费者:
首先我们运行3个消费者,然后不断的用produce去发送数据,我们可以看到消费者是通过一种轮询的方式进行不断的接受数据,每个消费者消费一个。
那么假如我们消费者收到了消息,然后处理这个消息需要30秒钟,在处理的过程中,消费者断电了宕机了,那消费者还没有处理完,我们设这个任务我们必须处理完,那我们应该有一个确认的信息,说这个任务完成了或者是没有完成,所以我的生产者要确认消费者是否把这个任务处理完了,消费者处理完之后要给这个生产者服务器端发送一个确认信息,生产者才会把这个任务从消息队列中删除。如果没有处理完,消费者宕机了,没有给生产者发送确认信息,那就表示没有处理完,那我们看看rabbitMQ是怎么处理的
我们可以在消费者的callback中添加一个time.sleep()进行模拟宕机。callback是一个回调函数,只要事件一触发就会调用这个函数。函数执行完了就代表消息处理完了,如果函数没有处理完,那就说明。。。。
我们可以看到在消费者代码中的basic_consume()中有一个参数叫no_ack=True,这个意思是这条消息是否被处理完都不会发送确认信息,一般我们不加这个参数,rabbitMQ默认就会给你设置成消息处理完了就自动发送确认,我们现在把这个参数去掉,并且在callback中添加一句话运行:ch.basic_ack(delivery_tag=method.delivery_tag)(手动处理)
def callback(ch, method, properties, body):#回调函数
print("---->",ch,method,properties)
#time.sleep(30)
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
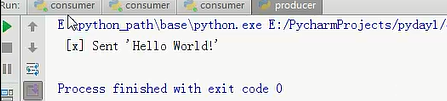


运行的结果就是,我先运行一次生产者,数据被消费者1接收到了,但是我把消费者1宕机,停止运行,那么消费者2就接到了消息,即只要消费者没有发送确认信息,生产者就不会把信息删除。
RabbitMQ消息持久化:
我们可以生成好多的消息队列,那我们怎么查看消息队列的情况呢:rabbitmqctl.bat list_queues

现在的情况是,消息队列中还有消息,但是服务器宕机了,那这个消息就丢了,那我就需要这个消息强制的持久化:
channel.queue_declare(queue='hello2',durable=True)
在每次声明队列的时候加上一个durable参数(客户端和服务器端都要加上这个参数),

在这个情况下,我们把rabbitMQ服务器重启,发现只有队列名留下了,但是队列中的消息没有了,这样我们还需要在生产者basic_publish中添加一个参数:properties
producer:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
#声明一个管道
channel = connection.channel()
#声明queue
channel.queue_declare(queue = 'hello2',durable=True)
#routing_key是queue的名字
channel.basic_publish(exchange='',
routing_key='hello2',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2,#make message persistent
)
)
print("[x] Send 'Hello World!'")
connection.close()
这样就可以使得消息持久化
现在是一个生产者对应三个消费者,很公平的收发收发,但是实际的情况是,我们机器的配置是不一样的,有的配置是单核的有的配置是多核的,可能i7处理器处理4条消息的时候和其他的处理器处理1条消息的时间差不多,那差的处理器那里就会堆积消息,而好的处理器那里就会形成闲置,在现实中做运维的,我们会在负载均衡中设置权重,谁的配置高权重高,任务就多一点,但是在rabbitMQ中,我们只做了一个简单的处理就可以实现公平的消息分发,你有多大的能力就处理多少消息
即:server端给客户端发送消息的时候,先检查现在还有多少消息,如果当前消息没有处理完毕,就不会发送给这个消费者消息。如果当前的消费者没有消息就发送
这个只需要在消费者端进行修改加代码:
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello2',durable=True)
def callback(ch, method, properties, body):#回调函数
print("---->",ch,method,properties)
#time.sleep(30)
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,#如果收到消息,就调用callback来处理消息
queue='hello2',
#no_ack=False
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
我们在生成一个consume2,在callback中sleep20秒来模拟



我先启动两个produce,被consume接受,然后在启动一个,就被consumer2接受,但是因为consumer2中sleep20秒,处理慢,所以这时候在启动produce,就又给了consume进行处理
前面都是1对1的发送接收数据,那我想1对多,想广播一样,生产者发送一个消息,所有消费者都收到消息。那我们怎么做呢?这个时候我们就要用到exchange了
exchange在一端收消息,在另一端就把消息放进queue,exchange必须精确的知道收到的消息要干什么,是否应该发到一个特定的queue还是发给许多queue,或者说把他丢弃,这些都被exchange的类型所定义
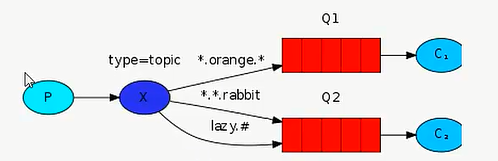
exchange在定义的时候是有类型的,以决定到底是那些queue符合条件,可以接受消息:
fanout:所有bind到此exchange的queue都可以接受消息
direct:通过rounroutingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey的routingKey所bind的queue可以接受消息
headers:通过headers来决定把消息发给哪些queue
消息publisher:
1 import pika
2 import sys
3
4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
5
6 channel = connection.channel()
7
8 channel.exchange_declare(exchange='log',type = 'fanout')
9
10 message = ' '.join(sys.argv[1:]) or 'info:Hello World!'
11 channel.basic_publish(exchange='logs',routing_key='',body=message)
12 print("[x] Send %r " % message)
13 connection.close()
这里的exchange之前是空的,现在赋值log;在这里也没有声明queue,广播不需要写queue
消息subscriber:
1 import pika
2 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
3 channel = connection.channel()
4 channel.exchange_declare(exchange='logs',exchange_type='fanout')
5
6 #exclusive唯一的,不指定queue名字,rabbit会随机分配一个名字
7 #exclusive=True会在使用此queue的消费者断开后,自动将queue删除
8 result = channel.queue_declare(exclusive=True)
9 queue_name = result.method.queue
10
11 channel.queue_bind(exchange='logs',queue=queue_name)
12
13 print('[*] Waiting for logs,To exit press CTRL+C')
14
15 def callback(ch,method,properties,body):
16 print("[X] %r" % body)
17 channel.basic_consume(callback,queue = queue_name,no_ack=True)
18 channel.start_consuming()
在消费者这里我们有定义了一个queue,注意一下注释中的内容。但是我们在发送端没有声明queue,为什么发送端不需要接收端需要呢?在consume里有一个channel.queue_bind()函数,里面绑定了exchange转换器上,当然里面还需要一个queue_name
运行结果:




就相当于收音机一样,实时广播,打开三个消费者,生产者发送一条数据,然后3个消费者同时接收到
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据关键字判定应该将数据发送到指定的队列

publisher:
1 import pika
2 import sys
3 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
4 channel = connection.channel()
5
6 channel.exchange_declare(exchange='direct_logs',exchange_type='direct')
7
8 severity = sys.argv[1] if len(sys.argv)>1 else 'info'
9 message = ' '.join(sys.argv[2:]) or 'Hello World!'
10 channel.basic_publish(exchange='direct_logs',routing_key=severity,body=message)
11
12 print("[X] Send %r:%r" %(severity,message))
13 connection.close()
subscriber:
import pika
import sys
connect = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connect.channel()
channel.exchange_declare(exchange='direct_logs',exchange_type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]#
if not severities:
sys.stderr.write("Usage:%s [info] [warning] [error]\n" %sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=severity)
print('[*]Waiting for logs.To exit press CTRL+c')
def callback(ch,method,properties,body):
print("[x] %r:%r"%(method.routing_key,body))
channel.basic_consume(callback,queue = queue_name,no_ack=True)
channel.start_consuming()
更加细致的过滤(exchange_type=topic)
publish:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
subscriber:
1 import pika
2 import sys
3
4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
5 channel = connection.channel()
6
7 channel.exchange_declare(exchange='topic_logs',
8 exchange_type='topic')
9
10 result = channel.queue_declare(exclusive=True)
11 queue_name = result.method.queue
12
13 binding_keys = sys.argv[1:]
14 if not binding_keys:
15 sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
16 sys.exit(1)
17
18 for binding_key in binding_keys:
19 channel.queue_bind(exchange='topic_logs',
20 queue=queue_name,
21 routing_key=binding_key)
22
23 print(' [*] Waiting for logs. To exit press CTRL+C')
24
25
26 def callback(ch, method, properties, body):
27 print(" [x] %r:%r" % (method.routing_key, body))
28
29
30 channel.basic_consume(callback,
31 queue=queue_name,
32 no_ack=True)
33
34 channel.start_consuming()
以上都是服务器端发消息,客户端收消息,消息流是单向的,那如果我们想要发一条命令给远程的客户端去执行,然后想让客户端执行的结果返回,则这种模式叫做rpc
RabbitMQ RPC

rpc server:
1 import pika
2 import time
3 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
4 channel = connection.channel()
5
6 channel.queue_declare(queue='rpc_queue')
7 def fib(n):
8 if n==0:
9 return 0
10 elif n==1:
11 return 1
12 else:
13 return fib(n-1)+fib(n-2)
14
15 def on_request(ch,method,props,body):
16 n = int(body)
17 print("[.] fib(%s)" %n)
18 response = fib(n)
19
20 ch.basic_publish(exchange='',routing_key=props.reply_to,
21 properties=pika.BasicProperties(correlation_id=props.correlation_id),
22 body = str(response))
23 ch.basic_ack(delivery_tag=method.delivery_tag)25 channel.basic_consume(on_request,queue='rpc_queue')
26
27 print("[x] Awaiting rpc requests")
28 channel.start_consuming()
rpc client:
1 import pika
2 import uuid,time
3 class FibonacciRpcClient(object):
4 def __init__(self):
5 self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
6
7 self.channel = self.connection.channel()
8
9 result = self.channel.queue_declare(exclusive=True)
10 self.callback_queue = result.method.queue
11
12 self.channel.basic_consume(self.on_response,#回调函数,只要一收到消息就调用
13 no_ack=True,queue=self.callback_queue)
14
15 def on_response(self,ch,method,props,body):
16 if self.corr_id == props.correlation_id:
17 self.response = body
18
19 def call(self,n):
20 self.response = None
21 self.corr_id = str(uuid.uuid4())
22 self.channel.basic_publish(exchange='',routing_key='rpc_queue',
23 properties=pika.BasicProperties(
24 reply_to=self.callback_queue,
25 correlation_id=self.corr_id
26 ),
27 body=str(n),#传的消息,必须是字符串
28 )
29 while self.response is None:
30 self.connection.process_data_events()#非阻塞版的start_consuming
31 print("no message....")
32 time.sleep(0.5)
33 return int(self.response)
34 fibonacci_rpc = FibonacciRpcClient()
35 print("[x] Requesting fib(30)")
36 response = fibonacci_rpc.call(30)
37 print("[.] Got %r"%response)
之前的start_consuming是进入一个阻塞模式,没有消息就等待消息,有消息就收过来
self.connection.process_data_events()是一个非阻塞版的start_consuming,就是说发了一个东西给客户端,每过一点时间去检查有没有消息,如果没有消息,可以去干别的事情
reply_to = self.callback_queue是用来接收反应队列的名字
corr_id = str(uuid.uuid4()),correlation_id第一在客户端会通过uuid4生成,第二在服务器端返回执行结果的时候也会传过来一个,所以说如果服务器端发过来的correlation_id与自己的id相同 ,那么服务器端发出来的结果就肯定是我刚刚客户端发过去的指令的执行结果。现在就一个服务器端一个客户端,无所谓缺人不确认。现在客户端是非阻塞版的,我们可以不让它打印没有消息,而是执行新的指令,这样就两条消息,不一定按顺序完成,那我们就需要去确认每个返回的结果是哪个命令的执行结果。
总体的模式是这样的:生产者发了一个命令给消费者,不知道客户端什么时候返回,还是要去收结果的,但是它又不想进入阻塞模式,想每过一段时间看这个消息收回来没有,如果消息收回来了,就代表收完了。
运行结果:

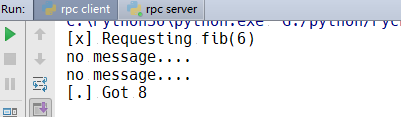
服务器端开启,然后在启动客户端,客户端先是等待消息的发送,然后做出反应,直到算出斐波那契
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复
python求numpy中array按列非零元素的平均值案例
网友评论