一财,花都论坛,篱歌 秋红叶
1、前言
因为负责基础服务,经常需要处理一些数据,但是大多时候采用awk以及java程序即可,但是这次突然有百万级数据需要处理,通过awk无法进行匹配,然后我又采用java来处理,文件一分为8同时开启8个线程并发处理,但是依然处理很慢,处理时长起码在1天+所以无法忍受这样的处理速度就采用python来处理,结果速度有了质的提升,大约处理时间为1个小时多一点,这个时间可以接受,后续可能继续采用大数据思想来处理,相关的会在后续继续更新。
2、安装python
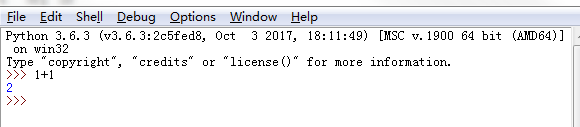
第一步首先下载软件,在官网可以根据自己情况合理下载,大家也可以通过进行下载其余就是下一步搞定,然后在开始里面找到python的exe,点击开然后输入1+1就可以看出是否安装成功了.如下图
3、ieda编辑器如何使用python
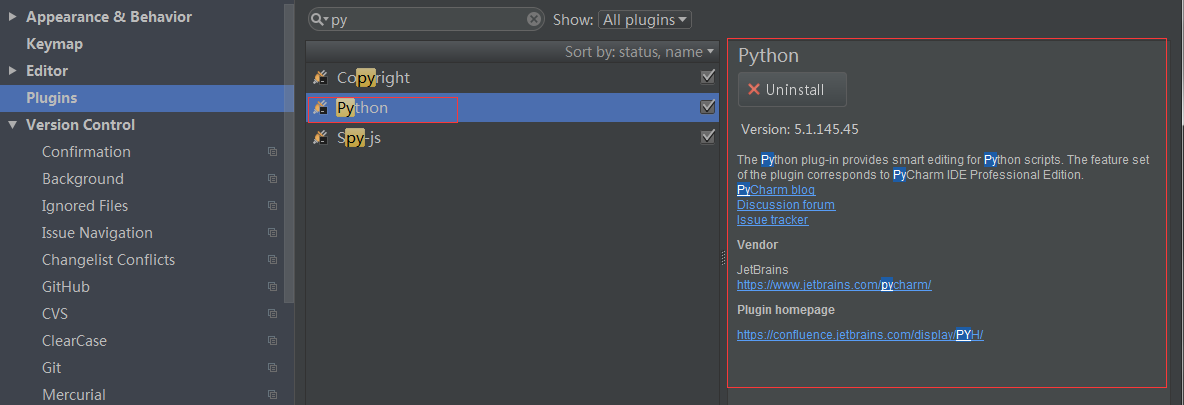
首先我们在idea中打开设置然后点击plugins,在里面有个输入框中输入python,根据提示找到如下的这个(idea版本不同可能影响python版本)
然后开始创建idea工程
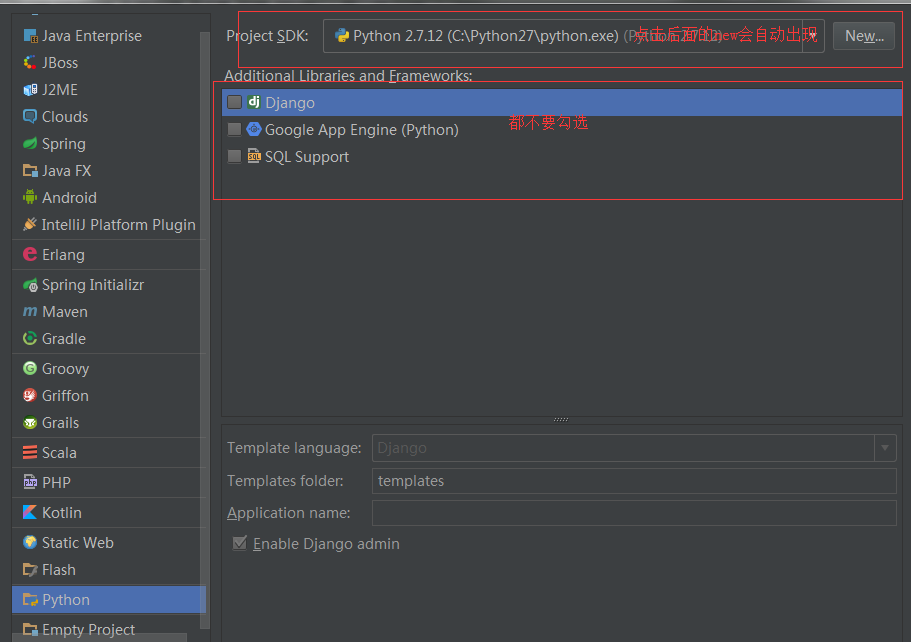
file->new->project->python然后出现如下图情况(其他的下一步然后就会创建工程了)
4、开发前知识准备
文件的读取,python读取文件非常的简单,我现在直接贴代码提供给大家
def readdata(filename): result = "" count=0 with open(filename, 'r') as f: for line in f.readlines(): result += line count += 1 print count return result """写入文件""" def writedata(filename, data): with open(filename, 'a+')as f: f.write(data)
其中def是函数的定义,如果我们写定义一个函数直接前面加上def,返回值可以获取后直接用return即可
python我们直接采用with open('文件路径',模式) as f的方式来打开文件
模式:
| r | 只读 | 文件不存在则出错 |
| r+ | 支持读写 | 文件不存在则出错,写入时,会覆盖源文件 |
| w | 只写 | 如果文件不存在则创建文件,会覆盖源文件,如果写入内容少则保留为覆盖的内容 |
| w+ | 支持读写 | 同上 |
| a | 只写 | 如果文件不存在则创建文件,会采用追加模式 |
| a+ | 读写 | 同上 |
| b | 二进制读写 |
跨文件引用:
同一个层级python是采用import直接导入文件名的方式,看下一个代码
import ioutils
filename1 = 'd:\\works\\pythons\\files\\userids.txt'
userids = ioutils.readdata(filename1).split('\n')
filename2 = 'd:\\works\\pythons\\files\\records.txt'
records = ioutils.readdata(filename2).strip()
recordsarr = records.split('\n')
count=0;
for data in recordsarr:
count+=1
if data.split('\t')[2] in userids:
ioutils.writedata('d:\\works\\pythons\\files\\20180604.txt', data + '\n')
print count
其他说明:
其中split和java程序的split一样,strip是去掉空格换行符等,循环(for in)模式,判断某个元素是否在数组中存在则直接使用 元素 in 数组
5、总结
如果你有数据量级别在百分的时候我建议优先可以想到python处理真的特别方便,而且很简单学习成本也很低,但是却很实用,其实awk在数据处理中也发挥很大的作用,大家可以私下学习,如果有时间我会分享一些,关于数据我这里就不提供了大家可以按照我上述代码跑就可以,更细节的我推荐看廖雪峰的python教程。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对移动技术网的支持。
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复





Python 实现将numpy中的nan和inf,nan替换成对应的均值


python爬虫把url链接编码成gbk2312格式过程解析

网友评论