法则执掌,win7 32位旗舰版,网址你懂得
总是聊并发的话题,聊到大家都免疫了,所以这次串讲下个话题——数据库(欢迎纠正补充)
看完问自己一个问题来自我检测:nosql我到底该怎么选?
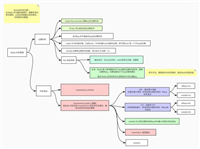
主要有这么三大类:[再老的数据库就不说了]
来看个权威的图:(红色的是推荐nosql,灰色是传统sql)

先说下nosql不是不要使用传统sql了,而是不仅仅是传统的sql(not only sql)
先看看传统数据库的好处:
当然了也有不足的地方:
保留字段也不人性化啊主从复制,读数据在salver进行到没啥事,但是大量写数据库怼到master上去就吃不消了,必须得加主数据库了。数据不一致(同样数据在两个主数据库更新成不一样的值),这时候得结合分库分表,把表分散在不同的主数据库中。sqlserver绝对是最佳选择,能省去很多时间)现在说说nosql了:(其实你可以理解为:nosql就是对原来sql的扩展补充)
如果还是不清楚到底怎么选择nosql,那就再详细说说每个类型的特点:
键值存储,代表=>redis(支持持久化和数据恢复,后面我们会详谈)mongodb 4.0开始支持acid事务了)类json格式,表结构修改比较方便)hbase
回头还是要把并发剩余几个专题深入的,认真看的同志会发现不管什么语言底层实现都是差不多的。
比如说进程,其底层就是用到了我们第一讲说的os.fork。再说进(线)程通信,讲的pipe、fifo、lock、semaphore等很少用吧?但是queue底层就是这些实现的,不清楚的话怎么读源码?
还记得当时引入queue篇提到java里的countdownlatch吗?要是不了解condition怎么自己快速模拟一个python里面没有的功能呢?
知其然不知其所以然是万万不可取的。等后面讲mq的时候又得用到queue的知识了,可谓一环套一环~
既然不是公司的萌妹子,所以呢~技术的提升还是得靠自己了^_^,先到这吧,最后贴个常用解决方案:
python、netcore常用解决方案(持续更新)
https://github.com/lesschina
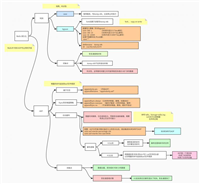
上篇提到了acid这次准备说说,然后再说说cap和数据一致性
以小明和小张转账的例子继续说说:
cap是分布式系统需要考虑的三个指标,数据共享只能满足两个而不可兼得:

代表:传统关系型数据库
如果想避免分区容错性问题的发生,一种做法是将所有的数据(与事务相关的)都放在一台机器上。虽然无法100%保证系统不会出错,但不会碰到由分区带来的负面效果(会严重的影响系统的扩展性)
作为一个分布式系统,放弃p,即相当于放弃了分布式,一旦并发性很高,单机服务根本不能承受压力。像很多银行服务,确确实实就是舍弃了p,只用高性能的单台小型机保证服务可用性。(所有nosql数据库都是假设p是存在的)
代表:zookeeper、redis(分布式数据库、分布式锁)
相对于放弃“分区容错性“来说,其反面就是放弃可用性。一旦遇到分区容错故障,那么受到影响的服务需要等待数据一致(等待数据一致性期间系统无法对外提供服务)
代表:dns数据库(ip和域名相互映射的分布式数据库,联想修改ip后为什么ttl需要10分钟左右保证所有解析生效)

反dns查询:
放弃强一致,保证最终一致性。所有的nosql数据库都是介于cp和ap之间,尽量往ap靠,(传统关系型数据库注重数据一致性,而对海量数据的分布式处理来说可用性和分区容错性优先级高于数据一致性)eg:
不同数据对一致性要求是不一样的,eg:

传统关系型数据库一般都是使用悲观锁的方式,但是例如秒杀这类的场景是hou不动,这时候往往就使用乐观锁了(cas机制,之前讲并发和锁的时候提过),上面也稍微提到了不同业务需求对一致性有不同要求而cap不能同时满足,这边说说主要就两种:
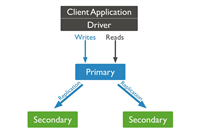
分布式事物来保证数据一致性了(这就是问什么项目里面经常提到的原因)redis的aof)quorum系统nrw策略(常用)quorum是集合a,a是全集u的子集,a中任意取集合b、c,他们两者都存在交集。
nrw算法:
r + w > n就可以保证强一致性(读取数据的节点和被同步写入的节点是有重叠的)比如:n=3,w=2,r=2(有一个节点是读+写)扩展:
r + w <= n,这时候读写不会在一个节点上同时出现,系统只能保证最终一致性。副本达到一致性的时间依赖于系统异步更新的方式,不一致性时间=从更新节点~所有节点都异步更新完毕的耗时r = w = n/2 + 1,这样性价比高,eg:n=3,w=2,r=2(3个节点==>1写,1读,1读写)参考文章:
http://book.51cto.com/art/201303/386868.htm https://blog.csdn.net/jeffsmish/article/details/54171812
数据更新+消息通信(数据同步):
其实还有很多策略来保证,这些概念的对象逆天不是很熟~比如:向量时钟策略
推荐几篇文章:
https://www.cnblogs.com/yanghuahui/p/3767365.html http://blog.chinaunix.net/uid-27105712-id-5612512.html https://blog.csdn.net/dellme99/article/details/16845991 https://blog.csdn.net/blakefez/article/details/48321323
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复

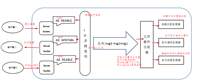
理解Redis持久化,RDB持久化和AOF持久化的不同处理方式

Redis 两类持久化方式,快照和全量追加日志的不同处理方式
网友评论