楚天风采22选5开奖结果,朗诵技巧,阿sue水果雪糕店
字典又称为符号表、关联数组或映射(map),是一种用于保存键值对(key-value)的数据结构。
那么 c 语言中有没有这样 key-value 型的内置数据结构呢? 答案:没有。
说起键值对,是不是想到了 java 中的 map?java中的 map 实现有两个:hashmap 和 treemap。
hashmap的底层是 hash 表,treemap 的底层是二叉搜索树,而 redis 必须要求的一点就是效率,所以 redis 中的字典使用的是 hash 表。
那么下面我们就拿 redis 中的字典与 java 中的 hashmap 对比一下
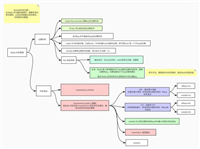
redis 中字典的底层使用的 hash 表,它的具体结构如下:
/*
* 字典
*
* 每个字典使用两个哈希表,用于实现渐进式 rehash
*/
typedef struct dict {
// 特定于类型的处理函数
dicttype *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2 个)
dictht ht[2];
// 记录 rehash 进度的标志,值为 -1 表示 rehash 未进行
int rehashidx;
} dict;
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictentry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
/*
* 哈希表节点
*/
typedef struct dictentry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 链往后继节点
struct dictentry *next;
} dictentry;
哈希表的基本结构这里就不再解释了,不知道的可以百度一下。这里解释一下 dict 中的内容,如下(出自《redis设计与实现第二版》第四章:字典):

java 中 hashmap 的具体实现就不多说了,结构和上面不一样。
当要将一个新的键值对添加到字典里面时,需要先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引下面。
redis 是通过 murmurhash2 算法求出 key 的 hash 值;java 是通过引入 hashcode 的概念计算 hash 值。
当有两个或以上的键值对被分配到 hash 表数组的同一个索引上面时,即发生了 hash 冲突。那么 redis 如何解决的 hash 冲突呢?
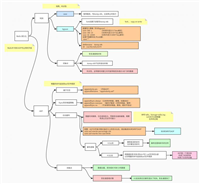
这就用到 dictentry 结构的 next 节点了,通过 next 将 hash 表节点串起来。例:k1-v1 和 k2-v2 分配到了同一个索引下,示意图如下(出自《redis设计与实现第二版》第四章:字典):

所以,理论上来说在特殊情况下 hash 会退化成链表。而 java 为了解决 hash 表退化的问题,在 jdk1.8 的 hashmap 中引入了红黑树。
随着操作的不断进行,哈希表保存的键值对会逐渐的增多或减少,如果hash表保存的键值对过多,会影响查询的效率;反之,如果过小,又会浪费空间。所以程序就需要对哈希表的大小进行相应的扩容或者收缩。
无论扩容还是收缩,都涉及到三个问题:
(1)触发条件是什么?是手动触发还是自动触发。
(2)扩容或者收缩的规则是什么?具体过程是怎样的?
(3)当哈希表在扩容时,是否允许别的线程来操作这个哈希表?
** redis 的实现**
redis 中的扩展和收缩是通过 rehash 操作完成的,扩容的触发条件是:
1) 当服务器没有执行 bgsave 命令或者 bgrewriteaof 命令时,负载因子大于等于 1 时触发。
2) 当服务器正在执行 bgsave 命令或者 bgrewriteaof 命令时,负载因子大于等于 5 时触发。
其中:哈希表的负载因子 = 哈希表已保存节点数量 / 哈希表总长度。
收缩的条件是:哈希表的负载因子 < 0.1。
扩容的规则是:扩容至第一个大于等于 ht[0].used(当前包含键值对数量)* 2 的 2^n;
收缩的规则是:收缩至第一个大于等于 ht[0].used(当前包含键值对数量)* 2 的 2^n;
扩容和收缩的过程一样,都是:
1) 为字典的 ht[1] 哈希表分配空间。
2) 将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上。
3) 释放 ht[0] ,ht[1] = ht[0],再为 ht[1] 新创建一个空的哈希表。
当 redis 中的哈希表在扩容时,必须得能允许别的请求来操作哈希表。否则一旦要rehash一个很大的哈希表时,就得拒绝所有对该哈希表的请求,这是不被允许的。所以 redis 在上面的第二步(rehash)是渐进式 rehash 的。rehash的详细步骤如下(出自《redis设计与实现第二版》第四章:字典):

因为在进行渐进式 rehash 的过程中,字典会同时使用 ht[0] 和 ht[l] 两个哈希表,所以在渐进式 rehash 进行期间,字典的删除(delete)、査找(find)、更新(update)等操作,会在两个哈希表上进行。例如,要在字典里面査找一个键的话,程序会先在ht[0]里面进行査找,如果没找到的话,就会继续到ht[l]里面进行査找,诸如此类。
另外,在渐进式 rehash 执行期间,新添加到字典的键值对一律会被保存到 ht[l] 里面, 而 ht[0] 则不再进行任何添加操作,这一措施保证了 ht[0] 包含的键值对数量会只减不 增,并随着 rehash 操作的执行而最终变成空表。
渐进式 rehash 的好处在于既将哈希表的扩容操作变成了线程安全的,又把计算量分摊到了对字典的每个增删改查操作上面。
上一篇遗留的问题:
redis 中的 sds(simple dynamic string)、java中的 (stringbuilder、stringbuffer、arraylist ),他们的扩容规则分别是什么呢?
redis 中的 sds 的扩容规则是:
java中:
stringbuilder 和 stringbuffer 都继承了 abstractstringbuilder,扩容规则都是:扩容至 newcapacity 和 oldcapacity * 2 + 2 的最大值。部分代码如下:
private int newcapacity(int mincapacity) {
// overflow-conscious code
int newcapacity = (value.length << 1) + 2;
if (newcapacity - mincapacity < 0) {
newcapacity = mincapacity;
}
return (newcapacity <= 0 || max_array_size - newcapacity < 0)
? hugecapacity(mincapacity)
: newcapacity;
}arraylist:如果容量允许的情况下扩容至 newcapacity 和 oldcapacity + oldcapacity / 2 的最大值。 部分代码如下:
private void grow(int mincapacity) {
// overflow-conscious code
int oldcapacity = elementdata.length;
int newcapacity = oldcapacity + (oldcapacity >> 1);
if (newcapacity - mincapacity < 0)
newcapacity = mincapacity;
if (newcapacity - max_array_size > 0)
newcapacity = hugecapacity(mincapacity);
// mincapacity is usually close to size, so this is a win:
elementdata = arrays.copyof(elementdata, newcapacity);
}本篇介绍了 redis 中有关扩容和收缩的3个问题,那么对应的 java 中 hashmap 关于扩容和收缩的问题又是怎么处理的呢?
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复

理解Redis持久化,RDB持久化和AOF持久化的不同处理方式

Redis 两类持久化方式,快照和全量追加日志的不同处理方式

网友评论