risc-v架构和指令集凭借其开放特性,正赢得越来越广泛的关注,无论是中国还是intel、三星、高通等巨头都大力投入,risc-v也被视为arm乃至是x86的潜在“备胎”。
其实,nvidia对于risc-v架构也非常关注,早早就加入了risc-v基金会,并做了不少研究,近日还公开了在深度神经网络(dnn)中应用risc-v指令集的可能。
nvidia表示,dnn需要高性能、高精度,对功耗也比较敏感,打造dnn加速器并不容易,成本也很高,所以计划使用低功耗、高带宽的芯片互连技术,将多个推理加速芯片组成一个mesh网格网络。
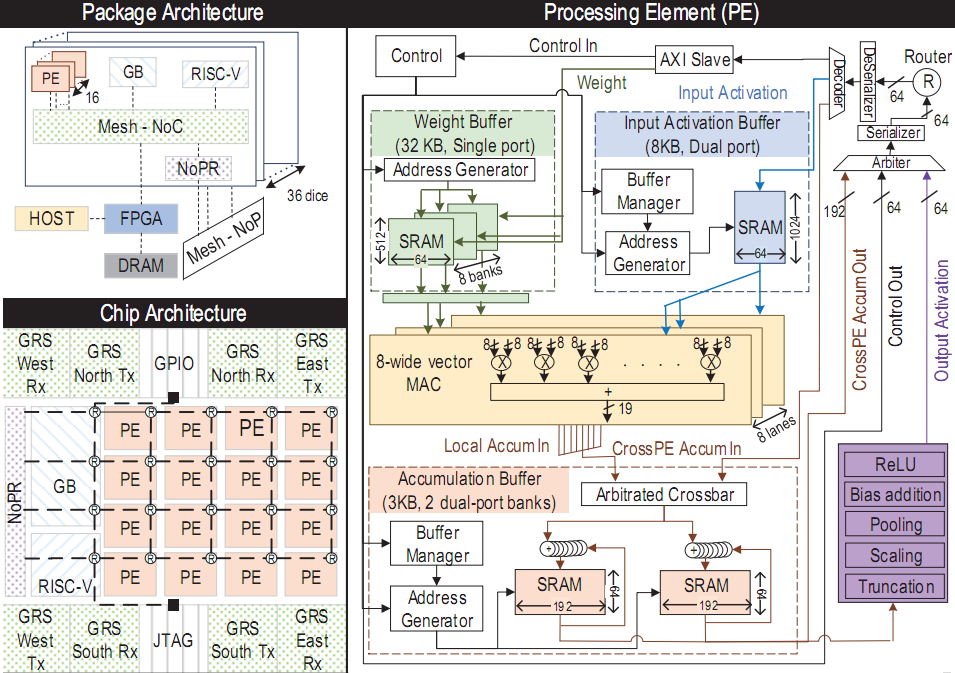
封装架构、芯片架构、pe结构
在一款研究性芯片中,nvidia设计了16个用于深度学习计算的处理元件(pe),搭配一个采用risc-v指令集的控制器,可提供4.01tops(每秒4.01万亿次操作)的算力,支持最多36块芯片互连,总算力达到128tops。
使用台积电16nm工艺时,单个芯片封装面积6平方毫米(2.4×2.5毫米),内核面积3.1平方毫米,36块芯片互连就是总封装面积216平方毫米、总内核面积111.6平方毫米,仍然在可控范围内,而且算下来能效可达1.15tops每平方毫米。
不过,nvidia这项研究只是一种方向性探索,暂时不会有对应的商用产品,但思路可能会融入到未来的架构和产品设计中。

如对本文有疑问, 点击进行留言回复!!

2年升级一次 Intel:10nm、7nm及5nm工艺开发不会削减投资



AMD推土机FX-8350超频至8.1GHz!却打不过3.6GHz锐龙
网友评论