ai(人工智能)是当今科技圈的热门话题,深度学习则是ai训练的重要手段之一。如何学习要靠硬件和算法支撑,这方面,intel力挺cpu,nvidia则力挺gpu。
日前,intel实验室联合美国莱斯大学宣布了一种突破性的深度学习新算法slide。
slide基于散列开发,而非当前最富盛名的bp算法(反向传播算法)所基于的矩乘。
借助slide,cpu用于传统ai模型深度学习训练的效率大大提升。研究论文举例称,一套拥有44个xeon核心的平台和一套价值10万美元、由8张nvidia vlta v100加速卡支撑的平台(tensorflow框架)执行相同的训练任务,前者用时1小时,后者则花了3.5小时。
有趣的是,intel还表示,它们这套平台尚未充分优化,还是“残血”状态,比如处理器的dlboost并未启用。
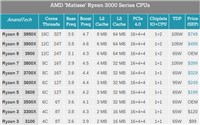
不过,这套44核至强平台到底是什么型号cpu并未公布,一说就是22核心44线程的至强铂金6238,一说是双路至强铂金6238,还有可能是未发布的产品。

如对本文有疑问, 点击进行留言回复!!

2年升级一次 Intel:10nm、7nm及5nm工艺开发不会削减投资



AMD推土机FX-8350超频至8.1GHz!却打不过3.6GHz锐龙
网友评论