望庐山瀑布ppt,高速公路天气预报,红木家具价格走势
#-*-coding:utf-8-*-
import redis
# 连接池连接使用,节省了每次连接用的时间
conn_pool = redis.connectionpool(host='localhost',port=6379)
# 第一个客户端访问
re_pool = redis.redis(connection_pool=conn_pool)
# 第二个客户端访问
re_pool2 = redis.redis(connection_pool=conn_pool)
# key value存储到redis数据库
try:
re_pool.set('chinese1', 'hello_world')
re_pool2.set('chinese2', 'hello_python')
except exception as e:
print(e)
# 根据key获取存的数据的内容
data_info = re_pool.get('chinese1')
data_info2 = re_pool.get('chinese2')
# 输出从redis库中取出来的数据的内容
print(data_info)
print(data_info2)
# 获取两个连接的信息
id1 = re_pool.client_list()
id2 = re_pool2.client_list()
# 输出两个连接的id,判断是否一致
print('re_pool_id{}======re_pool2_id{}'.format(id1[0]['id'], id2[0]['id']))
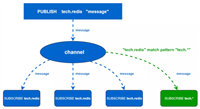
redis的队列效率高,而且简单易用。
从左往右插入队列
查看插入的数据
import redis
import json
# redis连接
re_queue = redis.redis(host='localhost', port=6379 )
# 顺序插入五条数据到redis队列,sort参数是用来验证弹出的顺序
num = 0
for i in range(0, 5):
num = num + 1
# params info
params_dict = {"channel":"facebook", "operate":"publish", "sort":num}
# 从左往右入队到redis
re_queue.lpush("params_info", json.dumps(params_dict))
# 查看目标队列数据
result = re_queue.lrange("params_info", 0, 10)
print(result)
# 结果输出
# [b'{"channel": "facebook", "operate": "publish", "sort": 5}', b'{"channel": "facebook", "operate": "publish", "sort": 4}', b'{"channel": "facebook", "operate": "publish", "sort": 3}',
b'{"channel": "facebook", "operate": "publish", "sort": 2}', b'{"channel": "facebook", "operate": "publish", "sort": 1}']
从左往右,第一个进的肯定是在最右边,要处理第一个,就要从右往左弹出
rpush从右往左入队,第一个在最左边,lpop从左边弹出
返回列表的长度
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复

理解Redis持久化,RDB持久化和AOF持久化的不同处理方式

Redis 两类持久化方式,快照和全量追加日志的不同处理方式
网友评论