2012年,深度学习算法在图像分类竞赛中展现出的显著性能提升引发了新一轮的ai热潮。
2015年,深度学习算法对芯片的快速增长需求引发了ai芯片创业热潮。

不过,拥抱ai芯片的设计者们很快发现,使用经典冯诺依曼计算架构的ai芯片即使在运算单元算力大幅提升,但存储器性能提升速度较慢的情况下,两者的性能差距越来越明显,而深度学习算法带来的数据搬运消耗的能量是计算消耗能量的几十倍甚至几百倍,“内存墙”的问题越来越显著。

因此,依靠软件算法以及云端强大计算能力的人工智能虽然取得了较大的成功,可以胜任多种特定的智能处理任务,但是面临功耗、速度、成本等诸多挑战,离智能万物互联时代还有巨大差距。
ai芯片的核心技术之一就是解决“内存墙”挑战,可以在存储器内直接做计算的存内计算(in-memory computing)技术在沉寂了近30年后,ai热潮下近年来成为焦点。无论是顶级学术会议,还是巨头公司都在寻找能够用存内计算打破ai芯片“内存墙”的最佳技术方案。
那么,谁会是最终的破局者?
存内计算最适合ai?
存内计算被不少业内人士认为是最适合ai的芯片架构,广受学术界和产业界的青睐。
2018年,国际顶级学术会议-ieee国际固态电路会议(isscc)有一个专门的议程讨论存内计算。2019年和2020年关于存内运算的论文更是大爆发,isscc2020与存内计算相关的论文数量上升到了7篇。同时,2019年电子器件领域顶级会议iedm有三个专门的议程共二十余篇存内计算相关的论文。
除了学术界,产业界也越来越多的玩家布局该技术。ibm基于其独特的相变存内计算已经有了数年的技术积累;台积电正大力推进基于reram的存内计算方案;英特尔、博世、美光、lam research、应用材料、微软、亚马逊、软银则投资了基于nor flash的存内计算芯片。
其实,利用存储器做计算在很早以前就有人研究,上世纪90年代就有学者发表过相关论文。但没有人真正实现产业落地,究其原因,一方面是设计挑战比较大,更为关键的是没有杀手级应用。随着深度学习的大规模爆发,存内计算技术才开始产业化落地。
存内计算的产业化落地历程,与知存科技创始人的求学创业经历关系密切。
2011年,郭昕婕本科毕业于北大信息科学技术学院微电子专业,本科毕业之后郭昕婕开始了美国加州大学圣塔芭芭拉分校(ucsb)的博士学业,她的导师dmitri b.strukov教授是存内计算领域的学术大牛,2008年在惠普完成了忆阻器的首次制备,2010年加入了美国加州大学圣塔芭芭拉分校。郭昕婕也成为了dmitri b.strukov教授的第一批博士生,开始了基于nor flash存内计算芯片的研究。
dmitri b. strukov告诉她,flash已经商用几十年,技术成熟,成本很低,是最接近产业化的方向,但缺点同样是因为flash研究起步较早,学术界对flash存内计算的研究期望较高,发表文章不易。2013年,随着深度学习的研究热潮席卷学术界,在导师的支持下,郭昕婕开始尝试基于nor flash存内计算的芯片研发。
耗时4年,历经6次流片,郭昕婕终于在2016年研发出全球第一个3层神经网络的浮栅存内计算深度学习芯片,首次验证了基于浮栅晶体管的存内计算在深度学习应用中的效用。仅一年后,她就进一步攻下7层神经网络的浮栅存内计算深度学习芯片。
也是在2016年,郭昕婕的大学同学,也是她丈夫的王绍迪,同样看到了存内计算芯片在ai中的应用价值,选择和郭昕婕继续在博士后阶段从事存内计算的研究工作。2017年,美国开始大力资助存内计算技术的研发,王绍迪和其导师的项目也获得了600万美金的资助。郭昕婕夫妇认为时机成熟,毅然选择回国创业,并获得了启迪之星、兆易创新等关联人的投资支持。
2017年10月,知存科技在北京成立,由于积累了丰富的经验,知存科技在成立后的10个月内就首次流片。同时加上存内计算技术逐渐获得认可,知存科技的发展也在逐步加快,并于2018年12月获得获讯飞领投的天使+轮融资,2019年8月又获得中芯聚源领投的近亿元a轮融资。

测试晶圆图 来源:知存科技
王绍迪对存内计算技术在ai中的应用充满信心,他接受雷锋网采访时表示:“ai算法的参数越多,存内计算的优势越大。因为存内计算是在存储器中储存了一个操作数,输入另一个操作数后就可以得到运算结果。所以参数越多,节省的数据搬运就越多,优势也就越明显。存内计算可以看作是一个大的锤子,ai算法是钉子,早期落地的算法是小钉子,随着时间推演,钉子会越来越大越来越多。”

知存科技ceo王绍迪
知存科技的方案是从底层重新设计存储器,利用nor flash存储单元的物理特性,对存储阵列进行改造,重新设计外围电路使其能够容纳更多的数据,同时将算子也存储到存储器当中,使得每个单元都能进行模拟运算并且能直接输出运算结果,以达到存内计算的目的。
由此看来,存内计算是破解“内存墙”瓶颈的好方法,但为什么在多种存内计算的技术路径中,知存科技选择的是nor flash?
为什么选择nor-flash?
其实,能做存内计算的存储器并不多,除了flash,还有亿阻器、相变存储器、铁电存储器、自旋存储器、sram等,但各有各的优缺点。
综合来看,nor flash是目前最适合产业化的方向,众多巨头投资的美国初创公司mythic采用的也正是nor flash。至于为什么用nor flash做存内计算被业界看好,王绍迪表示:“单独从器件特性看,nor flash的优势不仅体现在功耗和成熟度等方面,高精度也是很大的优势。目前主要的问题是没有28nm以下的nor flash工艺,但是基于当前工艺的nor flash存内计算相比传统方案的优势已经足够高了。”
使用nor flash单元可以完成8bit权重存储和8bit * 8bit的模拟矩阵乘加运算。单一nor flash阵列可并行完成200万次矩阵乘加法运算,计算吞吐量相比dram和sram等存储器带宽高出100-1000倍。
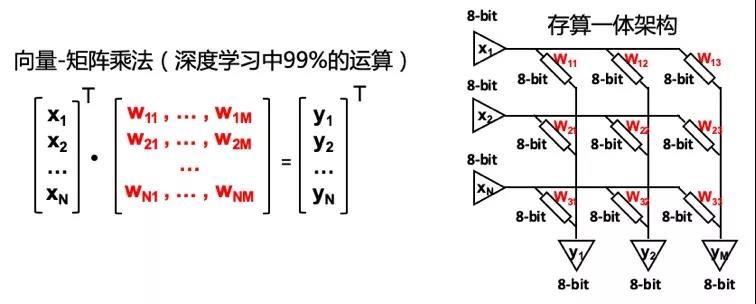
知存科技存算一体芯片技术
“相比使用数字电路计算,使用nor flash进行存内计算减少了数据搬运消耗的能量,再加上nor flash进行乘加法运算功耗也很低,这样就会带来百倍甚至千倍的功耗降低。”王绍迪表示。
当然,考虑到外围电路的功耗,nor flash存内计算最终能够实现的功耗降低在几十倍到上百倍之间。不同的算法和应用能够实现的提升也不同。
王绍迪介绍,目前来看nor flash存内计算技术可以在单芯片中支持到300m左右的深度学习权重参数,不需要额外的内存就可以进行计算。目前智能语音模型的大小通常在几百k到几兆的大小,端侧的图像推理模型大小通常在几兆到几十兆之间,因此nor flash存内计算芯片可以满足大部分ai场景的需求。
存内计算可以支持的模型精度可以达到现在主流的8比特。王绍迪说,8比特可以覆盖大部分的深度学习应用,即便有些极限场景需要更高的16比特,我们也有解决方案在研发。我们希望未来存内计算能够覆盖60%-70%的ai应用。
需要指出的是,知存科技的技术水平领先业界3-4年。郭昕婕博士在2012、2013年就开始研究基于norflash的存内计算技术,其他公司基本到2018年才开始研发投入。作为一项新兴前沿技术,研发存内计算需要大量的技术积累,存在许多坑需要一步一步去踩,即便其他公司投入大量资源,在不出现技术泄露的情况下,至少也得三四年左右的时间才能达到知科技存目前的成绩。
这其中的设计挑战,包含了控制电路、模拟电路、编程技术、可靠性设计、架构设计等。模拟设计就是其中非常大的挑战,由于flash进行的是模拟计算,但算法都是基于数字电路开发,这就对模拟运算增加了很多苛刻的要求。
王绍迪说:“虽然理论上存内计算芯片在功能上无需完全匹配现有的芯片,但目前业界的ai算法都是基于现有芯片架构开发的,因此知存科技的产品必须去适应这些商用算法,并且要做到高精度,这经历了一次次地流片迭代,这些经历和技术积累也成为了知存科技的优势。”
“在迭代的过程中,我们需要去解决工艺、温度、编程、噪声等带来的误差,同时还要解决一些模拟运算遇到的问题,解决问题的过程也是一个创新的过程。正如魏少军教授所说:产品创新是芯片设计企业的永恒话题。”他进一步表示。
而这也解释了知存科技选择nor flash的原因,从零开始设计nor flash存内计算芯片需要非常长的时间,nor flash之所以能比nand flash进度更快,是因为nor-flash已经有一套成熟的方案,可以基于已有的方案进行优化,更快推出产品。
谁是破局者?
经历了多次流片和技术迭代之后,知存科技上月底发布了两款智能语音芯片memcore001/memcore001p,支持智能语音识别、语音降噪、声纹识别等多种智能语音应用。芯片运行功耗小于300ua,待机功耗小于10ua。
根据知存科技的技术文档,memcore001/memcore001p典型工作频率为24mhz(工作时钟)和2mhz(唤醒时钟),memcore001p在低功耗模式下,采用片内独立的低功耗时钟,可与其他芯片通过中断协同交互,进一步降低整个系统的功耗。

memcore001系列芯片尺寸
memcore001/memcore001p内置2mb深度学习网络参数存储空间,可同时存储和运算多达32层的多个(相同或不同)深度学习网络算法,支持dnn/rnn/lstm/tdnn等多种网络结构。
作为协处理器,memcore001/memcore001p可兼容基于arm架构的cortex-m4/m3/m33/m0等系列mcu以及基于risc-v的mcu。
不过,芯片想要落地,还要把存内计算的硬件优势转化为落地优势。王绍迪表示,产品能落地仅有一点优势并不够,能否落地还要看市场的需求。当然,想要尽快落地,要做到让现在的商用算法在尽可能少做改变的同时尽快适配我们的芯片,这点非常重要的,这就需要和算法公司一起合作,在落地过程中不断了解需求,让软件和硬件协同起来,都发挥最大作用。
他进一步指出,软件平台可以让开发者在算法迁移和调试的时候更加方便。不过存内计算的工作方式比较简单,比如传统架构需要几百万个周期才能完成的计算,存内计算一个周期就可以完成,所以存内计算的编译器是粗颗粒度的,开发难度较低。
因此,知存科技与合作方开发了相应的系统解决方案,包含智能语音降噪和智能语音识别等算法,可直接集成在芯片中,供应用开发者方便调用。
与其它大部分ai芯片一样,知存科技的memcore001/memcore001p在进行算法迁移的时候也需要重新训练。这时候,如何才能吸引客户使用存内计算的芯片?
王绍迪说:“如果我的芯片能够带来的提升非常明显,或者原先不能落地的应用使用了我们的芯片之后可以落地,这样才有人愿意尝试。这样的场景很多,需要去探索,不过目前已经有意向客户准备使用我们的产品。”
知存科技在存内计算的领先性从另一个角度也能说明,“早期研发的时候,由于缺乏晶圆工厂和eda工具的支持,我们的开发工作很多就要从自动变成手动,但这同时让知存科技建立起了存内计算芯片的设计方法学。”王绍迪表示。
这样的领先让知存科技有可能成为存内ai芯片的破局者,知存科技的目标是在三年内实现5000万颗芯片的出货目标。对此,王绍迪表示乐观,他认为消费市场5000万的出货量并不多,如果选对了方向,一个产品的出货量在几年内就能达到上千万。
5000万的出货意味着公司可以实现盈利,在这样的目标下,硬件和软件都需要不断迭代。王绍迪透露,现在公司每三到四个月就会流片一次,一年会推出一款甚至两款新产品。视觉芯片的样片会在明年流片,预计后年会正式推出。
小结
作为ai发展的关键推动力,ai芯片能够在多大程度上满足ai算法的需求成为关键。要满足ai算法的需求就需要解决ai芯片内存墙的核心挑战,存内计算以其能够同时存储和计算的特性被视为解决内存墙挑战的一种方法,但其用模拟计算满足数字算法的需求,外围电路设计、软件设计、工艺带来的误差都是挑战。
存内计算的公司之间显然还不是竞争关系,但我们都期待存内计算ai芯片能够出现代表性地应用,推动ai的快速落地和持续发展。
如对本文有疑问, 点击进行留言回复!!

2年升级一次 Intel:10nm、7nm及5nm工艺开发不会削减投资



AMD推土机FX-8350超频至8.1GHz!却打不过3.6GHz锐龙
网友评论