兰州库房出租,绝对彼氏漫画下载,pk10助赢
mongodb的使用之前也分享过一篇,稍微高阶点:见这里:《mongodb使用小结》
1、shell登陆和显示
假设在本机上有一个端口为17380的mongodb服务,假设已经把mongo bin文件加入到系统path下。
登陆:mongo --port 17380
显示db:show dbs
进入某db:use test_cswuyg
显示集合:show tables
2、简单查找
查找文档:db.test_mac_id.find({'a': 'b'})
删除文档:db.test_mac_id.remove({'a': 'b'})
查找找到某一天的数据:
db.a.find({'d' : isodate('2014-04-21t00:00:00z')}) 或者 db.a.find({'d' : isodate('2014-04-21')})
删除某一天的数据:
db.region_mac_id_result.remove({"d" : isodate('2014-04-17')})
小于2014.6.5的数据:
db.xxx.find({e: {$lt :isodate('2014-06-05')}})
大于等于2014.6.1的数据:
db.xxx.find({e: {$gte: isodate("2014-05-29")}}).count()
两个条件:
db.xxx.find({e:{$gte: isodate("2014-05-29"), $lte: isodate("2014-06-04")}}).count()
json中的嵌套对象查询,采用“点”的方式:
mongos> db.wyg.find({"a.b": {$exists: true}})
{ "_id" : "c", "a" : { "b" : 10 } }
某个字段存在,且小于1000有多少:
db.stat.find({_: isodate("2014-06-17"), "123": {$exists: 1, $lte: 1000}}, {"123": 1}).count()
3、存在和遍历统计
存在'i': 1,且存在old_id字段:
mongos> var it = db.test.find({'i': 1, "old_id": {$exists: 1}})
遍历计数1:mongos> var count = 0;while(it.hasnext()){if (it.next()["x"].length==32)++count}print(count)
遍历计数2:mongos> var count = 0;while(it.hasnext()){var item = it.next(); if (item['x'].length==32 && item['_id'] != item['x'])++count;if(!item['x'])++count;}print(count)
4、插入和更新
> db.test.findone({_id: 'cswuyg'})
null
> db.test.insert({'_id': 'cswuyg', 'super_admin': true})
> db.test.findone({'_id': 'cswuyg'})
{
"_id" : "cswuyg",
"super_admin" : true
}
db.test.update({'_id': 'cswuyg'}, {$set: {'super_admin': true}})
5、repair 操作
对某个db执行repair:进入要repair的db,执行db.repairdatabase()
对mongodb整个实例执行repair:numactl --interleave=all /mongod --repair --dbpath=/home/disk1/mongodata/shard/
6、mongodb任务操作
停止某个操作:
[xxx]$ mongo --port 17380
mongodb shell version: 2.4.5
connecting to: 127.0.0.1:17380/test
mongos> db.currentop()
{ "inprog" : [ ...] }
mongos> db.killop("shard0001:163415563")
批量停止:
db.currentop().inprog.foreach(function(item){db.killop(item.opid)})
当查询超过1000秒的,停止:
db.currentop().inprog.foreach(function(item){if(item.secs_running > 1000 )db.killop(item.opid)})
停止某个数据源的查询:
db.currentop().inprog.foreach(function(item){if(item.ns == "cswuyg.cswuyg")db.killop(item.opid)})
把所有在等待锁的操作显示出来:
db.currentop().inprog.foreach(function(item){if(item.waitingforlock)print(json.stringify(item))})
把处于等待中的分片显示出来:
db.currentop().inprog.foreach(function(item){if(item.waitingforlock){print(item.opid.substr(0,9));print(item.op);}})
把非等待的分片显示出来:
db.currentop().inprog.foreach(function(item){if(!item.waitingforlock){var lock_info = item["opid"];print(lock_info.substr(0,9));print(item["op"]);}})
查找所有的查询任务:
db.currentop().inprog.foreach(function(item){if(item.op=="query"){print(item.opid);}})
查找所有的非查询任务:
db.currentop().inprog.foreach(function(item){if(item.op!="query"){print(item.opid);}})
查找所有的操作:
db.currentop().inprog.foreach(function(item){print(item.op, item.opid);});
常用js脚本,可直接复制到mongo-shell下使用:
显示当前所有的任务状态:
print("##########");db.currentop().inprog.foreach(function(item){if(item.waitingforlock){var lock_info = item["opid"];print("waiting:",lock_info,item.op,item.ns);}});print("----");db.currentop().inprog.foreach(function(item){if(!item.waitingforlock){var lock_info = item["opid"];print("doing",lock_info,item.op,item.ns);}});print("##########");
杀掉某些特定任务:
(1)
db.currentop().inprog.foreach(function(item){if(item.waitingforlock){var lock_info = item["opid"];if(item.op=="query" && item.secs_running >60 && item.ns=="cswuyg.cswuyg"){db.killop(item.opid)}}})
(2)
db.currentop().inprog.foreach(function(item) {
var lock_info = item["opid"];
if (item.op == "query" && item.secs_running > 1000) {
print("kill", item.opid);
db.killop(item.opid)
}
})
7、删除并返回数据
old_item = db.swuyg.findandmodify({query: {"_id": "aabbccdd"}, fields:{"d": 1,'e':1, 'f':1}, remove: true})
fields里面为1的是要返回的数据。
8、分布式集群部署情况
(1) 细致到collection的显示:sh.status()
(2)仅显示分片:
use config; db.shards.find()
{ "_id" : "shard0000", "host" : "xxhost:10001" }
{ "_id" : "shard0001", "host" : "yyhost:10002" }
....
(3)
use admin
db.runcommand({listshards: 1})
列出所有的shard server
9、正则表达式查找
正则表达式查询:
mongos> db.a.find({"tt": /t*/i})
{ "_id" : objectid("54b21e0f570cb10de814f86b"), "aa" : "1", "tt" : "tt" }
其中i表明是否是case-insensitive,有i则表示忽略大小写
db.testing.find({"name":/[7-9]/})
当name的值为789这几个数字组成的字符串时,查询命中。
10、查询性能
db.testing.find({name: 123}).explain()
输出结果:
{
"cursor" : "basiccursor",
"ismultikey" : false,
"n" : 1,
"nscannedobjects" : 10,
"nscanned" : 10,
"nscannedobjectsallplans" : 10,
"nscannedallplans" : 10,
"scanandorder" : false,
"indexonly" : false,
"nyields" : 0,
"nchunkskips" : 0,
"millis" : 0,
"indexbounds" : {
},
"server" : "xxx:10001"
}
11、更新或插入
当该key不存在的时候执行插入操作,当存在的时候则不管,可以使用setoninsert
db.wyg.update({'_id': 'id'}, {'$setoninsert': {'a': 'a'}, '$set': {'b': 'b'}}, true)
当id存在的时候,忽略setoninsert。
当id存在的时候,如果要插入,则插入{'a': 'a'}
最后的参数true,则是指明,当update不存在的_id时,执行插入操作。默认是false,只更新,不插入。
push、setoninsert:db.cswuyg.update({"_id": "abc"}, {$push: {"name": "c"}, $setoninsert: {"cc":"xx"}}, true)
12、计算db中collection的数量
db.system.namespaces.count()
13、增加数字,采用$inc
db.cswuyg.update({"a.b": {$exists: true}}, {$inc: {'a.b': 2}})
也就是对象a.b的值,增加了2
注意$inc只能用于数值。
14、删除某个key
db.cswuyg.update({'_id': 'c'}, {$unset: {'b': {$exists: true}}})
{ "_id" : "c", "a" : { "b" : 12 }, "b" : 7 }
转变为:
{ "_id" : "c", "a" : { "b" : 12 } }
15、增加key:value
db.cswuyg.update({'_id': 'z'}, {'$set': {'hello': 'z'}})
{ "_id" : "z", "b" : 1 }
转变为:
{ "_id" : "z", "b" : 1, "hello" : "z" }
16、删除数据库、删除表
删除数据库:db.dropdatabase();
删除表:db.mytable.drop();
17、查找到数据只看某列
只显示key名为d的数据:db.test.find({}, {d: 1})
18、查看分片存储情况
(1)所有db的分片存储信息,包括chunks数、shard key信息:db.printshardingstatus()
(2)db.collection.getsharddistribution() 获取collection各个分片的数据存储情况
(3)sh.status() 显示本mongos集群所有db的信息, 包含了shard key信息
19、查看collection的索引
db.cswuyg.getindexes()
20、开启某collection的分片功能
1. ./bin/mongo –port 20000
2. mongos> use admin
3. switched to db admin
4. mongos> db.runcommand({'enablesharding"' 'test'})
5. { "ok" : 1 }
开启user collection分片功能:
1. mongos> db.runcommand({'shardcollection': 'test.user', 'key': {'_id': 1}})
{ "collectionsharded" : "test.user", "ok" : 1 }
21、判断当前是否是shard集群
isdbgrid:用来确认当前是否是 sharding cluster
> db.runcommand({isdbgrid:1});
是:
{ "isdbgrid" : 1, "hostname" : "xxxhost", "ok" : 1 }
不是:
{
"ok" : 0,
"errmsg" : "no such cmd: isdbgrid",
"code" : 59,
"bad cmd" : {
"isdbgrid" : 1
}
}
22、$addtoset、$each插入数组数据
mongos> db.cswuyg.find()
{ "_id" : "wyg", "a" : "c", "add" : [ "a", "b" ] }
mongos> db.cswuyg.update({"_id": "wyg"}, {"$set": {"a": "c"}, "$addtoset": {"add": {"$each" :["a", "c"]}}}, true)
mongos> db.cswuyg.find()
{ "_id" : "wyg", "a" : "c", "add" : [ "a", "b", "c" ] }
$each是为了实现list中的每个元素都插入,如果没有$each,则会把整个list作为一个元素插入,变成了2维数组。
$addtoset会判断集合是否需要排重,保证集合不重。$push可以对数组添加元素,但它只是直接插入数据,不做排重。
eg:db.test.update({"a": 1}, {$push: {"name": {$each:["a", "c"]}}})
eg:db.test.update({"a": 1}, {$addtoset: {"name": {$each: ["a", "d"]}}})
不去重插入 pushall
> db.push.insert({"a": "b", "c": ["c", "d"]})
> db.push.find()
{ "_id" : objectid("53e4be775fdf37629312b96c"), "a" : "b", "c" : [ "c", "d" ]
}
> db.push.update({"a":"b"}, {$pushall:{"c": ["z", "d"]}})
> db.push.find()
{ "_id" : objectid("53e4be775fdf37629312b96c"), "a" : "b", "c" : [ "c", "d",
"z", "d" ] }
pushall跟push类似,不同的是pushall可以一次插入多个value,而不需要使用$each。
23、刷新配置信息
db.runcommand("flushrouterconfig");
24、批量更新
db.xxx.update({"_id": {$exists: 1}}, {$set: {"_" : isodate("2014-03-21t00: 00:00z")}}, true, true)
最后一个参数表示是否要批量更新,如果不指定,则一次只更新一个document。
25、dump db
mongodump支持从db磁盘文件、运行中的mongod服务中dump出bson数据文件。
(1)关闭mongod之后,从它的db磁盘文件中dump出数据(注:仅限单实例mongod):
mongodump --dbpath=/home/disk1/mongodata/shard/ -d cswuyg -o /home/disk2/mongodata/shard
参考:
(2)从运行的mongod中导出指定日期数据,采用-q查询参数:
mongodump -h xxxhost --port 17380 --db cswuyg --collection test -q "{d: {\$gte: {\$date: `date -d "20140410" +%s`000}, \$lt: {\$date: `date +%s`000}}}"
mongodump -dbpath=/home/disk3/mongodb/data/shard1/ -d cswuyg -c test -o /home/disk9/mongodata/shard1_2/ -q "{_:{\$gte:{\$date:`date -d "20140916" +%s`000}, \$lt: {\$date: `date -d "20140918" +%s`000}}}"
dump出来的bson文件去掉了索引、碎片空间,所有相比db磁盘文件要小很多。
26、restore db
restore的时候,不能先建索引,必须是restore完数据之后再建索引,否则restore的时候会非常慢。而且一般不需要自己手动建索引,在数据bson文件的同目录下有一个索引bson文件(system.indexes.bson),restore完数据之后会mongorestore自动根据该文件创建索引。
(1)从某个文件restore
mongorestore --host xxxhost --port 17380 --db cswuyg --collection cswuyg ./cswuyg_1406330331/cswuyg/cswuyg_bak.bson
(2)从目录restore
./mongorestore --port 27018 /home/disk2/mongodata/shard/
(3)dump 和 restore configure server:
mongodump --host xxxhost --port 19913 --db config -o /home/work/cswuyg/test/config
mongorestore --host xxxhost --port 19914 /home/work/cswuyg/test/config
27、创建索引
看看当前的test collection上有啥索引:
mongos> db.test.getindexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "cswuyg.test",
"name" : "_id_"
}
]
当前只有_id这个默认索引,我要在test collection上为 index 字段创建索引:
mongos> db.test.ensureindex({"index": 1})
创建完了之后,再看看test collection上的索引有哪些:
mongos> db.test.getindexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "cswuyg.test",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"index" : 1
},
"ns" : "cswuyg.test",
"name" : "index_1"
}
]
创建索引,并指定过期时间:db.a.ensureindex({'_':-1}, {expireafterseconds: 1000}) 1000second.
修改过期时间: db.runcommand({"collmod": "a", index: {keypattern:{"_": -1}, expireafterseconds: 60}})
28、删除索引
db.post.dropindexes() 删除post上所有索引
db.post.dropindex({name: 1}) 删除指定的单个索引
29、唯一索引问题
如果集群在_id上进行了分片,则无法再在其他字段上建立唯一索引:
mongos> db.a.ensureindex({'b': 1}, {'unique': true})
{
"raw" : {
"set_a/xxxhost:20001,yyyhost:20002" : {
"createdcollectionautomatically" : false,
"numindexesbefore" : 1,
"ok" : 0,
"errmsg" : "cannot create unique index over { b: 1.0 } with shard key pattern { _id: 1.0 }",
"code" : 67
},
"set_b/xxxhost:30001,yyyhost:30002" : {
"createdcollectionautomatically" : false,
"numindexesbefore" : 1,
"ok" : 0,
"errmsg" : "cannot create unique index over { b: 1.0 } with shard key pattern { _id: 1.0 }",
"code" : 67
}
},
"code" : 67,
"ok" : 0,
"errmsg" : "{ set_a/xxxhost:20001,yyyhos:20002: \"cannot create unique index over { b: 1.0 } with shard key pattern { _id: 1.0 }\", set_b/xxxhost:30001,yyyhost:30002: \"cannot create unique index over { b: 1.0 } with shard key pattern { _id: 1.0 }\" }"
}
之所以出现这个错误是因为mongodb无法保证集群中除了片键以外其他字段的唯一性,能保证片键的唯一性是因为文档根据片键进行切分,一个特定的文档只属于一个分片,mongodb只要保证它在那个分片上唯一就在整个集群中唯一,实现分片集群上的文档唯一性一种方法是在创建片键的时候指定它的唯一性。
30、因迁移导致出现count得到的数字是真实数字的两倍
cswuyg> db.test.find({d: isodate('2015-08-31'), b: 'active'}).count()
52118
cswuyg> db.test.find({d: isodate('2015-08-31'), b: 'active'}).foreach(function(item){db.test_count.insert(item)})
cswuyg> db.test_count.count()
26445
解决方法:
“on a sharded cluster, count can result in an inaccurate count if orphaned documents exist or if a chunk migration is in progress.
to avoid these situations, on a sharded cluster, use the $group stage of the db.collection.aggregate()method to $sum the documents. ”
31、自定义mongodb操作函数
可以把自己写的js代码保存在某个地方,让mongodb加载它,然后就可以在mongodb的命令行里操作它们。
mongodb shell默认会加载~/.mongorc.js文件
例如以下修改了启动提示文字、左侧提示文字,增加了my_show_shards shell函数用于显示当前sharded collection的chunks在各分片的负载情况:
//~/.mongorc.js
//show at begin
var compliment = ["attractive", "intelligent", "like batman"];
var index = math.floor(math.random()*3);
print("hello, you're looking particularly " + compliment[index] + " today!");
//change the prompt
prompt = function(){
if (typeof db == "undefined") {
return "(nodb)> ";
}
// check the last db operation
try {
db.runcommand({getlasterror: 1});
}
catch (e) {
print(e);
}
return db + "> ";
}
//show all shard's chunks
function my_show_shards() {
var config_db = db.getsiblingdb("config");
var collections = {};
var shards = {};
var shard_it = config_db.chunks.find().snapshot();
while (shard_it.hasnext()) {
next_item = shard_it.next();
collections[json.stringify(next_item["ns"]).replace(/\"/g, "")] = 1;
shards[json.stringify(next_item["shard"]).replace(/\"/g, "")] = 1;
}
var list_collections = [];
var list_shards = [];
for (item in collections) {
list_collections.push(item);
}
for (item in shards) {
list_shards.push(item);
}
list_collections.foreach(function(collec) {
list_shards.foreach(function(item) {
obj = {};
obj["shard"] = item;
obj["ns"] = collec;
it = config_db.chunks.find(obj);
print(collec, item, it.count());
})
})
}
32、关闭mongod
mongo admin --port 17380 --eval "db.shutdownserver()"
33、查看chunks信息
eg: 进入到config db下,执行
db.chunks.find()
34、预分片参考
35、db重命名
db.copydatabase("xx_config_20141113", "xx_config")
use xx_config_20141113
db.dropdatabase();
远程拷贝db :
db.copydatabase(fromdb, todb, fromhost, username, password)
db.copydatabase("t_config", "t_config_v1", "xxxhost: 17380")
这个拷贝过程很慢。
注意,sharded的db是无法拷贝的,所以sharded的db也无法采用上面的方式重命名。
参考: "your remote database is sharded through mongos."
拷贝collection:
db.collection.copyto("newcollection")
同样,sharded的collection也无法拷贝。36、聚合运算
包括:
1、pipeline;
2、map-reduce
管道:
2.6之前的mongodb,管道不支持超过16mb的返回集合。
可以使用$out操作符,把结果写入到collection中。如果aggregation成功,$out会替换已有的colleciton,但不会修改索引信息,如果失败,则什么都不做。
37、aggregate pipeline demo
cswuyg_test> db.cswuyg_test.aggregate({"$match": {"_": isodate("2015-02-16"), "$or": [{"13098765": {"$exists": true}}, {"13123456": {"$exists": true}}]}}, {"$group": {"_id": "$_", "13098765": {"$sum": "$13098765"}, "13123456":{"$sum": "$13123456"}}})
demo2,使用磁盘:
db.test.aggregate([{'$match': {'d': {'$nin': ['a', 'b', 'c']}, '_': {'$lte': isodate("2015-02-27"), '$gte': isodate("2015-02-26")}}}, {'$group': {'_id': {'a': '$a', 'b': '$b', 'd': '$d'}, 'value': {'$sum': 1}}}], {'allowdiskuse': true})
db.cswuyg.aggregate([ {'$match': {'d': {'$nin': ['a', 'b', 'c']}, '_': {'$lte': isodate("2015-02-10"), '$gte': isodate("2015-02-09")}}}, {'$group': {'_id': {'c': '$c', 'd': '$d'}, 'value': {'$sum': 1}}}, {"$out": "cswuyg_out"}], {'allowdiskuse':true})
db.b.aggregate([{$match: {a: {$size: 6}}}, {$group: {_id: {a: '$a'}}}, {$out: 'hh_col'}], {allowdiskuse: true})
注:指定输出文档,只能输出到本db下。
aggregate练习:
pymongo代码:
[{'$match': {u'i': {u'$in': [xxx']}, u'h': u'id', u'12345678': {u'$exists': true}, '_':{'$lte': datetime.datetime(2015, 6, 1, 23, 59, 59), '$gte': datetime.datetime(2015, 6, 1, 0, 0)}}}, {'$group': {'_id': {u'12345678': u'$12345678', u'g': u'$g'}, 'value': {'$sum': 1}}}]
shell下代码:
db.test.aggregate([{$match: {_:isodate("2015-06-01"), "h": "id", "12345678": {"$exists": true}, "i": "xxx"}}, {$group: {_id: {"12345678": "$12345678", "g": "$g"}, "value": {"$sum": 1}}}], {allowdiskuse:true})
38、修改key:value中的value
给字段b的值加上大括号'{':
db.test.find({_:isodate("2014-11-02")}).foreach(function(item){if(/{.+}/.test(item["b"])){}else{print(item["b"]);db.test.update({"_id": item["_id"]}, {"$set": {"b": "{" + item["b"] + "}"}})}})
39、修改primary shard
db.runcommand({"moveprimary": "test", "to": "shard0000"})
这样子test db 里的非sharded cocllection数据就会被存放到shard0000中,非空db的话,可能会有一个migrate的过程。
40、 mongodb默认开启autobalancer
balancer是sharded集群的负载均衡工具,新建集群的时候默认开启,除非你在config里把它关闭掉:
config> db.settings.find()
{ "_id" : "chunksize", "value" : 64 }
{ "_id" : "balancer", "activewindow" : { "start" : "14:00", "stop" : "19:30" }, "stopped" : false}
activewindow指定autobalancer执行均衡的时间窗口。
stopped说明是否使用autobalancer。
手动启动balancer:sh.startbalancer()
判断当前balancer是否在跑:sh.isbalancerrunning()
41、mongodb插入性能优化
插入性能:200w的数据,在之前没有排序就直接插入,耗时4小时多,现在,做了排序,插入只需要5分钟。排序对于单机版本的mongodb性能更佳,避免了随机插入引发的频繁随机io。
排序:在做分文件排序的时候,文件分得越小,排序越快,当然也不能小到1,否则频繁打开文件也耗费时间。
42、mongodb数组操作
1、更新/插入数据,不考虑重复值:
mongos> db.test.update({"helo":"he2"}, {"$push": {"name":"b"}})
多次插入后结果:
{ "_id" : objectid("54a7aa2be53662aebc28585f"), "helo" : "he2", "name" : [ "a", "b", "b" ] }
2、更新/插入数据,保证不重复:
mongos> db.test.update({"helo":"she"}, {"$addtoset": {"name":"b"}})
writeresult({ "nmatched" : 1, "nupserted" : 0, "nmodified" : 0 })
多次插入后结果:
{ "_id" : objectid("54dd6e1b570cb10de814f86d"), "helo" : "she", "name" : [ "b" ] }
保证只有一个值。
3、数组元素个数:
$size 用来指定数组的元素个数,显示fruit数组长度为3的document:
mongos> db.a.find({"fruit": {$size: 3}})
{ "_id" : objectid("54b334798220cd3ad74db314"), "fruit" : [ "apple", "orange", "cherry" ] }
43、更换key: value中的key
verrelease 换为 test
db.test.find().foreach(function(item){db.test.update({_id:item["_id"]}, {"$set": {"test": item["verrelease"]}}, {"$unset":{"verrelease":{"exists":true}}})})
或者更新部分修改为:
db.test.update({d : isodate("2014-11-02")}, {$rename : {"act": "am"}}, false, true)
44、手动在shell下movechunk
config> sh.movechunk("xx.yy", { "_id" : { "d" : isodate("2015-02-24t00:00:00z"), "id" : "3f" } }, "shard0003")
如果出现错误,参考这里:可能需要重启
45、mongodb升级后的兼容问题
mongodb 2.4切换到2.6之后,出现数据没有插入,pymongo代码:
update_obj = {"$set" : {"a": 1}}
update_obj["$inc"] = inc_objs
update_obj["$push"] = list_objs
db.test.update({"_id": id}, update_obj, true)
2.6里,inc如果是空的,则会导致整条日志没有插入,2.4则inc为空也可以正常运行。
46、格式化json显示
db.collection.find().pretty()
47、更新replica集群的域名信息
cfg = rs.conf() cfg.members[0].host = "xxxhost: 20000" cfg.members[1].host = "yyyhost: 20001" cfg.members[2].host = "zzzhost: 20002" rs.reconfig(cfg)
48、不要直接修改local.system.replset
不要直接修改local.system.replset,因为他只能修改本机器的本地信息。
但是如果出现了:
{
"errmsg" : "exception: can't use localhost in repl set member names except when using it for all members",
"code" : 13393,
"ok" : 0
}
这样的错误,那就要修改本机的local.system.replset,然后重启。
49、排重统计
(1)aggregate
result = db.flu_test.aggregate([{$match: {_: isodate("2015-05-01")}}, {$group:{_id:"$f", value: {$sum:1}}}], {allowdiskuse:true})
result.itcount()
(2)distinct
flu_test> db.flu_test.distinct('f', {_:isodate("2015-06-22")})
但是,由于distinct将结果保存在list中,所以很容易触发文档超过16mb的错误:
2015-06-23t15:31:34.479+0800 distinct failed: {
"errmsg" : "exception: distinct too big, 16mb cap",
"code" : 17217,
"ok" : 0
} at src/mongo/shell/collection.js:1108
非排重文档量统计:
mongos> count = db.flu_test.aggregate([{$match:{_:isodate("2015-05-21")}}, {$group:{_id:null, value: {$sum:1}}}], {allowdiskuse:true})
{ "_id" : null, "value" : 3338987 }
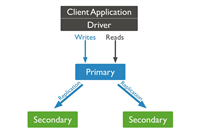
50、pymongo优先读取副本集secondary节点
优先读取副本集secondary节点,可以减少primary节点负担,在primary节点跟secondary节点同步延迟较短、业务对数据不要求实时一致时可以利用副本集做读写分离和负载均衡。
副本集集群的读取有这几种使用方式:
primary: 默认参数,只从主节点读取;
primarypreferred: 大部分从主节点上读取,主节点不可用时从secondary节点读取;
secondary: 只从secondary节点上进行读取操作;
secondarypreferred: 优先从secondary节点读取,secondary节点不可用时从主节点读取;
nearest: 从网络延迟最低的节点上读取。
(1)测试1 优先从secondary读取数据:
import pymongo
client = pymongo.mongoreplicasetclient('xxxhost: yyyport', replicaset='my_set', readpreference='secondarypreferred')
print client.read_preference # 显示当前的读取设定
for i in xrange(1, 10000): # 循环10000次,用mongostat观察查询负载
a = client['history']['20140409'].find_one({"ver_code": "128"})
print a
(2)测试2 直接连接某secondary节点读取数据:
import pymongo
client = pymongo.mongoclient('xxxhost', yyyport, slaveok=true)
a = client['msgdc_ip']['query_ip'].find().count()
print a
参考:
http://emptysqua.re/blog/reading-from-mongodb-replica-sets-with-pymongo/
注意:3.0之后mongoreplicasetclient函数是要被放弃的。
但是测试时发现:在较低版本中,需要使用mongoreplicasetclient,mongoclient无法实现 pymongo.readpreference.secondary_preferred功能。
2015.12.28补充:
51、为副本集设置标签
可以为副本集中的每个成员设置tag(标签),设置标签的好处是后面读数据时,应用可以指定从某类标签的副本上读数据。
为replica 设置tag
在副本shell下执行:
var conf = rs.conf()
conf.members[0].tags = { "location": "beijing" }
conf.members[1].tags = { "location": "hangzhou"}
conf.members[2].tags = { "location": "guangzhou" }
rs.reconfig(conf)
参考:
52、副本集碎片整理的一种方法
使用mmapv1存储引擎时,对于频繁大数据量的写入删除操作,碎片问题会变得很严重。在数据同步耗时不严重的情况下,我们不需要对每个副本做repair,而是轮流“卸下副本,删除对应的磁盘文件,重新挂上副本”。每个重新挂上的副本都会自动去重新同步一遍数据,碎片问题就解决了。
53、存储引擎升级为wiredtiger
我们当前的版本是mongodb3.0.6,没有开启wiredtiger引擎,现在打算升级到wiredtiger引擎。
我们是shared cluster,shard是replica set。升级比较简单,只需要逐步对每一个副本都执行存储引擎升级即可,不影响线上服务。
升级时,只在启动命令中添加:--storageengine wiredtiger。
步骤:首先,下掉一个副本;然后,把副本的磁盘文件删除掉;接着,在该副本的启动命令中添加--storageengine wiredtiger后启动。这就升级完一个副本,等副本数据同步完成之后,其它副本也照样操作(或者处理完一个副本之后,拷贝该副本磁盘文件替换掉另一个副本的磁盘文件)。风险:如果数据量巨大,且有建索引的需求,容易出现内存用尽。
分片集群的configure server可以不升级。
升级之后磁盘存储优化效果极度明显,22gb的数据会被精简到1.3gb。
升级后的磁盘文件完全变了,所以不同存储引擎下的磁盘文件不能混用。
升级参考:
54、oplogsizemb不要设置得太大
启动配置中的这个字段是为了设置oplog collection的大小,oplog是操作记录,它是一个capped collection,在副本集群中,设置得太小可能导致secondary无法及时从primary同步数据。默认情况下是磁盘大小的5%。但是,如果这个字段设置得太大,可能导致暴内存,oplog的数据几乎是完全加载在内存中,一旦太大,必然暴内存,导致oom。而且因为这个collection是capped,mongodb启动之后无法修改其大小。
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复

理解Redis持久化,RDB持久化和AOF持久化的不同处理方式

Redis 两类持久化方式,快照和全量追加日志的不同处理方式
网友评论