漫展网,西乡县政府网,盗窃罪
首先看一个常见的二叉排序树的操作,下面的代码包括插入、创建和中序遍历。摘自。
#include<stdio.h>
#include<stdlib.h>
typedef int elemtype;
struct btreenode
{
elemtype data;
struct btreenode* left;
struct btreenode* right;
};
//递归方式插入
void insert(struct btreenode** bst, elemtype x)
{
if (*bst == null) //在为空指针的位置链接新结点
{
struct btreenode* p = (btreenode*)malloc(sizeof(struct btreenode));
p->data = x;
p->left = p->right = null;
*bst = p;
}
else if (x < (*bst)->data) //向左子树中完成插入运算
insert(&((*bst)->left), x);
else
insert(&((*bst)->right), x); //向右子树中完成插入运算
}
//创建二叉搜索树,根据二叉搜索树的插入算法可以很容易实现
void createbstree(struct btreenode** bst, elemtype a[], int n)
{
int i;
*bst = null;
for (i = 0; i < n; i++)
insert(bst, a[i]);
}
void inorder_int(struct btreenode* bt)//中序遍历,元素类型为int
{
if (bt != null)
{
inorder_int(bt->left);
printf("%d,", bt->data);
inorder_int(bt->right);
}
}
//主函数
void main()
{
int x, *px;
elemtype a[10] = { 30,50,20,40,25,70,54,23,80,92 };
struct btreenode* bst = null;
createbstree(&bst, a, 10); //利用数组a建立一棵树根指针为bst的二叉搜索树
printf("进行相应操作后的中序遍历为:\n");
inorder_int(bst);
printf("\n");
printf("输入待插入元素值:");
scanf(" %d", &x);
insert(&bst, x);
printf("进行相应操作后的中序遍历为:\n");
inorder_int(bst);
printf("\n");
}
我一直很纳闷为什么插入(创建)操作需要传递指针的指针,不是指针就可以操作被指向的内容吗?为解决这个疑惑,首先看一下c语言的函数传参。
一个经典的例子就是交换两个数的值,swap(int a,int b),大家都知道这样做a和b的值不会被交换,需要swap(int *a,int *b)。从函数调用的形式看,传参分为传值和传指针两种(c++中还有传引用)。实际上在c语言中,值传递是唯一可用的参数传递机制,函数参数压栈的是参数的副本。传指针时压栈的是指针变量的副本,但当你对指针解指针操作时,其值是指向原来的那个变量,所以可以对原来变量操作。
再看一下前面的二叉树插入的例子。
btreenode *root=null; // step 1
insert(&root,x); // step 2
void insert(struct btreenode** bst, elemtype x)
{
if (*bst == null)
{
struct btreenode* p = (btreenode*)malloc(sizeof(struct btreenode)); // step 3
p->data = x;
p->left = p->right = null;
*bst = p; // step 4
}
...
}
函数递归调用,每次真正产生变化的时候传递进去的都是空指针。当树根为空时,我们图解看一下函数调用的值拷贝。

step 1 定义一个空指针root,&root为指针root的地址,图中的箭头表示指针的指向。
step 2 调用insert,产生一个&root的拷贝bst,即bst指向root。
step 3 生成一个新的节点为node,由指针p指向node。
step 4 (*bst)=p,也就是root的值为p(node的地址),于是root指向了新生成的节点。
如果我们把函数与调用改成一级指针,看下面的代码:
btreenode *root=null; // step 1
insert(root,x); // step 2
void insert(struct btreenode* bst, elemtype x)
{
if (bst == null)
{
struct btreenode* p = (btreenode*)malloc(sizeof(struct btreenode)); // step 3
p->data = x;
p->left = p->right = null;
bst = p; // step 4
}
...
}
再图解一下调用过程。

step 1 定义一个空指针root。
step 2 调用insert,产生一个root的拷贝bst,bst与root的值一样都为空,所以都没有指向。
step 3 生成一个新的节点为node,由指针p指向node。
step 4 bst=p,也就是bst的值为p(node的地址),于是bst指向了新生成的节点。
执行结束后我们得到了一个根节点但是root并没有指向这个节点。
那么能不能通过一级的指针就得到正确结果呢?答案是可以,看两个图的区别,其实就是root最后要指向node,即root=bst。所以只需要给函数加一个返回值,就可以通过一级指针得到同样的结果,看下面的代码:
//调用
root = insert_1(root,x);
//递归一级指针
btreenode* insert_1(struct btreenode* bst, elemtype x)
{
if (bst == null)
{
struct btreenode* p = (btreenode*)malloc(sizeof(struct btreenode));
p->data = x;
p->left = p->right = null;
bst = p;
}
else if (x < bst->data) //向左子树中完成插入运算
bst->left = insert_1(bst->left, x);
else
bst->right = insert_1(bst->right, x); //向右子树中完成插入运算
return bst;
}
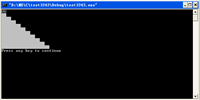
结果正确:

但是从语义上看,一级指针的写法没有二级指针那么直观,遇到需要对树进行修改的操作时还是用二级指针更好一点。
原文地址
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复
如何在没有core文件的情况下用dmesg+addr2line定位段错误
用QT制作3D点云显示器——QtDataVisualization
网友评论