八哥狗图片,谷建芬弟子规,日本裸体美女wwwxjeolcom
逗号分隔值(comma-separated values,csv,有时也称为字符分隔值,因为分隔字符也可以不是逗号):其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须象二进制数字那样被解读的数据。csv文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
csv文件格式的通用标准并不存在,但是在rfc 4180中有基础性的描述。使用的字符编码同样没有被指定,但是7-bit ascii是最基本的通用编码。
csv是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。最广泛的应用是在程序之间转移表格数据,而这些程序本身是在不兼容的格式上进行操作的(往往是私有的和/或无规范的格式)。因为大量程序都支持某种csv变体,至少是作为一种可选择的输入/输出格式。
“csv”并不是一种单一的、定义明确的格式(尽管rfc 4180有一个被通常使用的定义)。因此在实践中,术语”csv”泛指具有以下特征的任何文件:
(1)、纯文本,使用某个字符集,比如ascii、unicode、ebcdic或gb2312(简体中文)等;
(2)、由记录组成(典型的是每行一条记录);
(3)、每条记录被分隔符分隔为字段(典型分隔符有逗号、分号或制表符;有时分隔符可以包括可选的空格);
(4)、每条记录都有同样的字段序列。
在这些常规的约束条件下,存在着许多csv变体,故csv文件并不完全互通。然而,这些变异非常小,并且有许多应用程序允许用户预览文件(这是可行的,因为它是纯文本),然后指定分隔符、转义规则等。如果一个特定csv文件的变异过大,超出了特定接收程序的支持范围,那么可行的做法往往是人工检查并编辑文件,或通过简单的程序来修复问题。因此在实践中,csv文件还是非常方便的。
csv格式最好被用来表现记录集合或序列,其中的每条记录都有完全相同的字段序列。csv格式没有被限定于某个特定字符集。不管用unicode还是用ascii,都没有问题(尽管特定程序支持的csv可能会有它们自己的局限性)。甚至从一个字符集翻译到另一个字符集,csv文件都不会有问题(不象几乎所有的私有数据格式)。然而,csv不提供任何途径来表明使用的是什么字符集。
“csv”格式中大量变体的存在说明并没有一个”csv标准”。在常见用法中,几乎任何定界符分隔的文本数据都可以被统称为”csv”文件。不同的csv格式可能不会兼容。
以上内容介绍主要来自:维基百科
以下code是参考,可以实现对简单csv文件的解析:
如果csv文件比较复杂,可以试试github上的一个开源库:
parse_csv.hpp:
#ifndef fbc_cppbase_test_parse_csv_hpp_
#define fbc_cppbase_test_parse_csv_hpp_
// reference: https://stackoverflow.com/questions/1120140/how-can-i-read-and-parse-csv-files-in-c?page=1&tab=votes#tab-top
#include
#include
#include
#include
#include
#include
class csvrow {
public:
std::string const& operator[](std::size_t index) const { return m_data[index]; }
std::size_t size() const { return m_data.size(); }
void readnextrow(std::istream& str)
{
std::string line;
std::getline(str, line);
std::stringstream linestream(line);
std::string cell;
m_data.clear();
while (std::getline(linestream, cell, ',')) {
m_data.push_back(cell);
}
// this checks for a trailing comma with no data after it.
if (!linestream && cell.empty()) {
// if there was a trailing comma then add an empty element.
m_data.push_back("");
}
}
private:
std::vector m_data;
};
std::istream& operator>>(std::istream& str, csvrow& data)
{
data.readnextrow(str);
return str;
}
class csviterator {
public:
/*typedef std::input_iterator_tag iterator_category;
typedef csvrow value_type;
typedef std::size_t difference_type;
typedef csvrow* pointer;
typedef csvrow& reference;*/
csviterator(std::istream& str) :m_str(str.good() ? &str : nullptr) { ++(*this); }
csviterator() :m_str(nullptr) {}
// pre increment
csviterator& operator++() { if (m_str) { if (!((*m_str) >> m_row)){ m_str = nullptr; } }return *this; }
// post increment
csviterator operator++(int) { csviterator tmp(*this); ++(*this); return tmp; }
csvrow const& operator*() const { return m_row; }
csvrow const* operator->() const { return &m_row; }
bool operator==(csviterator const& rhs) { return ((this == &rhs) || ((this->m_str == nullptr) && (rhs.m_str == nullptr))); }
bool operator!=(csviterator const& rhs) { return !((*this) == rhs); }
private:
std::istream* m_str;
csvrow m_row;
};
#endif // fbc_cppbase_test_parse_csv_hpp_
test_parse_csv.cpp:
#include "test_parse_cvs.hpp"
#include
#include
#include
#include
#include "parse_csv.hpp"
namespace parse_cvs_ {
int test_parse_cvs_1()
{
std::ifstream file("e:/gitcode/messy_test/testdata/test_csv.csv");
std::vector> data;
csviterator loop(file);
for (; loop != csviterator(); ++loop) {
csvrow row = *loop;
std::vector tmp(row.size());
for (int i = 0; i < row.size(); ++i) {
tmp[i] = row[i];
}
data.emplace_back(tmp);
}
for (int i = 0; i < data.size(); ++i) {
for (int j = 0; j < data[i].size(); ++j) {
fprintf(stdout, "%s\t", data[i][j].c_str());
}
fprintf(stdout, "\n");
}
return 0;
}
} // namespace parse_cvs_
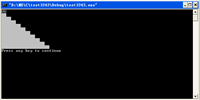
test_csv.csv测试数据如下:

执行结果如下:

如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复
如何在没有core文件的情况下用dmesg+addr2line定位段错误
用QT制作3D点云显示器——QtDataVisualization
网友评论