军人论坛,肯德基半价桶时间,dnf诡秘之森在哪
mongodb是非关系型数据库的典型代表,db-engines ranking 数据显示,近年来,mongodb在nosql领域一直独占鳌头。mongodb是为快速开发互联网应用 而设计的数据库系统,其数据模型和持久化策略就是为了构建高读/写的性能,并且可以方面的弹性拓展。目前公司使用到的mongodb的主要场景有 库存中心(原料出入库、商品出入库、商品上下架变动、与其它系统平台的交互报文等)、物流配送(订单的物流信息、配送信息、地理位置信息等)、日志中心(系统应用和app的log信息、调用依赖信息等)、商品中心(商品数据、推送信息等)、运维管理平台(收集记录的变更信息等)等。随着mongodb的普及和使用量的快速增长,为了规范使用,便于管理和获取更高的性能,整理此文档。我们从 数据库设计规范、集合设计规范、文档设计规范、连接规范、操作规范等5个方面进行阐述和要求。
(1)数据库名约定为小写。
(2)数据库名称不能包含除’_’以外的特殊字符,例如:/ \ . “ $。
(3)数据库名称最多为64个字符。
(4)数据库上线需经过dba评审。
(1)集合名称约定为小写。
(2)集合名称不能包含除’_’以外的特殊字符字符;集合名称禁止以system.开头。
(3)集合名称的最大长度为64个字符,包括前缀的【database.】内容。
(4)集合名称的命名规则和mysql数据库表的命名规则相同。
a) 同一模块的集合尽可能使用相同的前缀名,集合名称尽可能表达用途。
b) 数据表 <模块标识>_<表标识> 例如: order_header , order_detail
c) 编码表 base_<模块标识>_<表标识>
d) 日志表 log_<模块标识>_<表标识>
(5)固定集合可以用于记录日志,其插入数据更快,可以实现在插入数据时,淘汰最早的数据。固定集合需要显式创建,指定size的大小,还能够指定文档的数量。集合不管先达到哪一个限制,之后插入的新文档都会把最老的文档移出。
(6)索引命名:idx_<构成索引的字段名>。如果字段名字过长,可采用字段缩写。
(1)key的命名规范:不能以$开头;不能包含.(点号)。
(2)文档中的_id键推荐使用默认值,禁止向_id中保存自定义的值。
解读:mongodb文档中都会有一个“_id”键,默认是个objectid对象(标识符中包含时间戳、机器id、进程id和计数器)。mongodb在指定_id与不指定_id插入时速度相差很大,指定_id会减慢插入的速率。
(3)推荐使用短字段名。
解读:与关系型数据库不同,mongodb集合中的每一个文档都需要存储字段名,长字段名会需要更多的存储空间。
(4)禁止在同一个集合字段中存储多个数据类型的数据。
(5)如若将日期类型选择为string,不同的日期格式的文档,不支持等值查询,不支持范围查询。
解读:创建一个测试集合product,分别向集合插入date:"20180425"和date:"2018-04-25"两笔数据。等值查询、范围查询($gte, $lte)只能查到日期格式相同的数据,都为一笔数据。
(6)mongodb大小写敏感,如果字段无需大小写敏感,为了提高查询效率,应尽量在统一了大小写之后再插入到数据库中。
(7)mongodb是文档型数据库,数据以bson形式存储在文档中。mongodb能够支持最大16 mb的文档大小。建议尽量不要存储大型对象,将文档控制在16 mb以内。
(8)通过$size查询数组大小,但是$size运算符不使用索引和限制准确匹配(不能指定$sized 范围)。因此,如果需要基于数组的大小执行查询,可以在文档设计中增加size属性。
解读:例如在商品评价中,其他人可以对评价进行投票。为了阻止用户多次投票和对有帮助的评论进行排序,所以,评价文档设计是:在一个数组字段(voter_ids)保存了所有评论用户的id,而数组大小缓存在helpful_votes字段里。
(9)分片键必须有索引,分片键大小限制为512byte,一旦集合已经分片,不可以直接修改分片键。不接受向已进行分片的collection上插入无分片键的文档,也不支持空值插入。
(10)片键的设计原则:
a) 所有的插入、更新、删除将会均匀发送到集群的所有分片中。
b) 所有的查询将会在集群中的所有分片中均匀地分发。
c) 所有的更新或者删除操作将会只面向相关的分片,不会发送到一个没有存储被修改数据的分片上。
d) 一个查询将不会被发送到没有存储被查询数据的分片上。
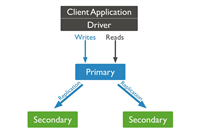
(1)正确连接副本集,副本集提供了数据的保护、高可用和灾难恢复的机制。如果主节点宕机,其中一个从节点会自动提升为从节点。
(2)合理控制连接池的大小,限制连接数资源,可通过connection string url中的maxpoolsize 参数来配置连接池大小。
(3)复制集读选项
默认情况下,复制集的所有读请求都发到primary,driver可通过设置的read preference 来将读请求路由到其他的节点。
a) primary:默认规则,所有读请求发到primary。
b) primarypreferred: primary优先,如果primary不可达,请求secondary。
c) secondary:所有的读请求都发到secondary。
d) secondarypreferred:secondary优先,当所有的secondary不可达时,请求primary。
e) nearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)。
(1)mongodb数据库更新文档有两种实现方式—文档替换和目标字段更新。既可以完整替换现有的文档,也可以使用更新操作符来修改某个字段。
解读:使用操作符,例如$set操作符和$push操作符,无论原始的大小,可以更新文档里的指定字段。频繁文档更新的场景下,使用目标更新可以在序列化和传输数据上花费更少的时间,获得更好的性能。
(2)多文档更新,在默认情况下,只会更新匹配查询器的第一个文档。要更新所有的匹配文档,需要显式指定多文档更新模式--添加参数multi:true。
(3)在文档级别更新是原子性的,这意味着一条更新10个文档的语句可能在更新3个文档后由于某些原因失败。应用程序必须根据自己的策略来处理这些失败。
(4)update结合upsert可以用来处理,当文档存在时更新,文档不存在时插入。如果查询选择器匹配,更新就正常执行;如果没有匹配的文档,就会插入新的文档。新文档的字段是查询选择器和目标更新文档的逻辑合并。
(5)复制集的数据安全及写策略,write concern 用于控制写入安全的级别。
解答:write concern 是一个性能和数据一致性的权衡,应根据业务场景进行设定。对于强一致性场景,建议w>1或者等于majority。
(6)聚合框架是mongodb的高级查询语言,它允许通过转换和合并由多个文档中的数据来生成新的单个文档里不存在的文档信息。可以把mongodb的聚合框架等价于sql的group by 语句。
(7)在聚合框架中,$project操作符允许过滤传递给管道下一个阶段的字段。限制每个文档传递的大小,可以改善性能,尤其是在处理大文档且只需要每个文档一部分数据的场景下。
本文版权归作者所有,未经作者同意不得转载,谢谢配合!!!
本文版权归作者所有,未经作者同意不得转载,谢谢配合!!!
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复

理解Redis持久化,RDB持久化和AOF持久化的不同处理方式

Redis 两类持久化方式,快照和全量追加日志的不同处理方式

网友评论