阴三儿 老师好,召唤光天使任务在哪,婚庆司仪主持词
/*******************************************************************************************************************
*文件说明:
* 第二个cuda程序------gpu设备性能参数的查询
*开发环境:
* win7+opencv2.4.8+cudatoolkit5.0+cuda sdk3.0+nivida nvs 3100m
*参考手册:
* cuda_toolkit_reference_manual.pdf
*时间地点:
* 陕西师范大学 2017.1.8
*作 者:
* 九月
*模块说明:
* 1--由于我们希望在【设备】上【分配内存】和【执行代码】,因此如果在程序中能够知道设备拥有多少【内存】以及具备
* 哪些功能,那么将非常的有用
* 2--而且,在一台计算机上拥有多个支持cuda的设备也是非常常见的情形。在这些情况中,我们希望通过某种方式来确定使用
* 的是哪一个gpu设备
* 3--在深入研究如何编写【设备代码】之前,我们需要通过某种机制来判断计算机中当前有哪些设备,以及每个设备都支持哪
* 些功能。
* 4--幸运的是,我们可以通过一个非常简单的接口来获得这样的信息
* 5--首先,我们希望知道在系统中有多少个设备是支持cuda的,并且这些设备能够运行基于cuda c编写的【核函数】
* 6--要获得cuda设备的数量,可以调用cudagetdevicecount()
* 7--在调用cudagetdevicecount()后,可以对每个设备进行迭代、并查询各个【设备】的【相关信息】。cuda运行时将返回一
* 个cudadeviceprop类型的结构,其中包含了设备的相关属性。
********************************************************************************************************************/
#include "cuda_runtime.h" //【1】cuda运行时头文件,包含了许多的runtime api
#include "device_launch_parameters.h"
#include <driver_types.h> //【2】驱动类型的头文件,包含cudadeviceprop【设备属性】
#include <cuda_runtime_api.h> //【3】cuda运行时api的头文件
#include "stdio.h"
#include <iostream>
/*******************************************************************************************************************
*模块说明:
* 控制台应用程序的入口函数----main函数
*函数说明:
*cudagetdevicecount函数原型:
* extern __host__ __cudart_builtin__ cudaerror_t cudartapi cudagetdevicecount(int *count)
*函数作用:
* 以*count的形式返回可用于执行的计算能力大于等于1.0的设备数量,如果不存在此设备,那么这个函数将会返回cudaerror
* -nodevice
********************************************************************************************************************/
int main()
{
cudadeviceprop strprop; //【1】定义一个【设备属性结构体】的【结构体变量】
int icount;
cudagetdevicecount(&icount); //【2】获得gpu设备的数量
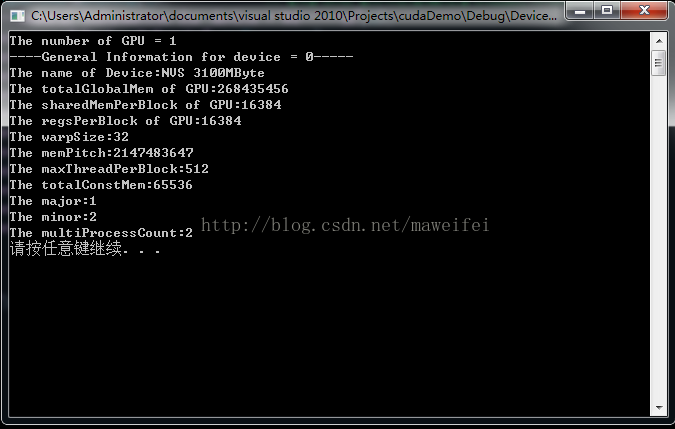
std::printf("the number of gpu = %d\n",icount);
for(int i=0;i<icount;i++) //【3】迭代的获取每一个【gpu设备】的属性
{
cudagetdeviceproperties(&strprop,i); //【4】获取【gpu设备属性】的函数,并将获得的设备属性存放在strprop中
std::printf("----general information for device = %d-----\n",i);
std::printf("the name of device:%s\n",strprop.name); //【1】nivida显卡的型号
std::printf("the totalglobalmem of gpu:%d\n",strprop.totalglobalmem); //【2】设备全局内存的总量,单位:字节
std::printf("the sharedmemperblock of gpu:%d\n",strprop.sharedmemperblock);//【3】在一个线程块block中可以使用的最大共享内存的数量
std::printf("the regsperblock of gpu:%d\n",strprop.regsperblock); //【4】每个线程块中可用的32位寄存器的数量
std::printf("the warpsize:%d\n",strprop.warpsize); //【5】每一个线程束包含的线程的数量
std::printf("the mempitch:%d\n",strprop.mempitch); //【6】内存复制中,最大的修正量
std::printf("the maxthreadperblock:%d\n",strprop.maxthreadsperblock); //【7】在一个线程块中,可以包含的最大线程数量
std::printf("the totalconstmem:%d\n",strprop.totalconstmem); //【8】常量内存的总量
std::printf("the major:%d\n",strprop.major);
std::printf("the minor:%d\n",strprop.minor);
std::printf("the multiprocesscount:%d\n",strprop.multiprocessorcount);
}
std::system("pause");
return 0;
}
struct __device_builtin__ cudadeviceprop
{
char name[256]; /**< ascii string identifying device */
size_t totalglobalmem; /**< global memory available on device in bytes */
size_t sharedmemperblock; /**< shared memory available per block in bytes */
int regsperblock; /**< 32-bit registers available per block */
int warpsize; /**< warp size in threads */
size_t mempitch; /**< maximum pitch in bytes allowed by memory copies */
int maxthreadsperblock; /**< maximum number of threads per block */
int maxthreadsdim[3]; /**< maximum size of each dimension of a block */
int maxgridsize[3]; /**< maximum size of each dimension of a grid */
int clockrate; /**< clock frequency in kilohertz */
size_t totalconstmem; /**< constant memory available on device in bytes */
int major; /**< major compute capability */
int minor; /**< minor compute capability */
size_t texturealignment; /**< alignment requirement for textures */
size_t texturepitchalignment; /**< pitch alignment requirement for texture references bound to pitched memory */
int deviceoverlap; /**< device can concurrently copy memory and execute a kernel. deprecated. use instead asyncenginecount. */
int multiprocessorcount; /**< number of multiprocessors on device */
int kernelexectimeoutenabled; /**< specified whether there is a run time limit on kernels */
int integrated; /**< device is integrated as opposed to discrete */
int canmaphostmemory; /**< device can map host memory with cudahostalloc/cudahostgetdevicepointer */
int computemode; /**< compute mode (see ::cudacomputemode) */
int maxtexture1d; /**< maximum 1d texture size */
int maxtexture1dmipmap; /**< maximum 1d mipmapped texture size */
int maxtexture1dlinear; /**< maximum size for 1d textures bound to linear memory */
int maxtexture2d[2]; /**< maximum 2d texture dimensions */
int maxtexture2dmipmap[2]; /**< maximum 2d mipmapped texture dimensions */
int maxtexture2dlinear[3]; /**< maximum dimensions (width, height, pitch) for 2d textures bound to pitched memory */
int maxtexture2dgather[2]; /**< maximum 2d texture dimensions if texture gather operations have to be performed */
int maxtexture3d[3]; /**< maximum 3d texture dimensions */
int maxtexturecubemap; /**< maximum cubemap texture dimensions */
int maxtexture1dlayered[2]; /**< maximum 1d layered texture dimensions */
int maxtexture2dlayered[3]; /**< maximum 2d layered texture dimensions */
int maxtexturecubemaplayered[2];/**< maximum cubemap layered texture dimensions */
int maxsurface1d; /**< maximum 1d surface size */
int maxsurface2d[2]; /**< maximum 2d surface dimensions */
int maxsurface3d[3]; /**< maximum 3d surface dimensions */
int maxsurface1dlayered[2]; /**< maximum 1d layered surface dimensions */
int maxsurface2dlayered[3]; /**< maximum 2d layered surface dimensions */
int maxsurfacecubemap; /**< maximum cubemap surface dimensions */
int maxsurfacecubemaplayered[2];/**< maximum cubemap layered surface dimensions */
size_t surfacealignment; /**< alignment requirements for surfaces */
int concurrentkernels; /**< device can possibly execute multiple kernels concurrently */
int eccenabled; /**< device has ecc support enabled */
int pcibusid; /**< pci bus id of the device */
int pcideviceid; /**< pci device id of the device */
int pcidomainid; /**< pci domain id of the device */
int tccdriver; /**< 1 if device is a tesla device using tcc driver, 0 otherwise */
int asyncenginecount; /**< number of asynchronous engines */
int unifiedaddressing; /**< device shares a unified address space with the host */
int memoryclockrate; /**< peak memory clock frequency in kilohertz */
int memorybuswidth; /**< global memory bus width in bits */
int l2cachesize; /**< size of l2 cache in bytes */
int maxthreadspermultiprocessor;/**< maximum resident threads per multiprocessor */
};
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复
如何在没有core文件的情况下用dmesg+addr2line定位段错误
用QT制作3D点云显示器——QtDataVisualization
网友评论