重庆红歌,林莹漫画,裔美声社
每个结点最多有两个孩子,其余结构和树的结构一样。
二叉树的特点有:
二叉树有五种基本形态:
斜树。所有结点只有左子树(或右子树)的二叉树称为左斜树(右斜树)。
满二叉树。所有结点(除了叶子结点)都存在左子树和右子树,且所有叶子结点均在同一层上。
满二叉树的特点有:
2;完全二叉树。对一棵具有n个结点的二叉树按层序编号,如果编号为i(1≤i≤n)的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,这个二叉树为完全二叉树。
图
完全二叉树的特点:
1,则该结点只有左孩子,即不存在只有右子树的情况;i层上至多有\(2^{i-1} (i≥1)\)个结点。k的二叉树至多有\(2^k-1 (k≥1)\)个结点。t,如果其终端结点数为\(n_0\),度为2的结点数为\(n_2\),则\(n_0=n_2+1\)。n个结点的完全二叉树的深度为\([log_2n]+1\)([x]表示不大于x的最大整数)。n个结点的完全二叉树,其结点按照层序编号,对任意结点\(i (1≤i≤n)\)有:
i是二叉树的根,无双亲;如果\(i≥1\),则其双亲结点为\([i/2]\)。i无左孩子(结点i为叶子结点);否则其左孩子是结点2i。i无右孩子;否则其右孩子是结点\(2i+1\)。遍历二叉树的方法:
先序遍历
dlr模式2.中序遍历
ldr模式后序遍历
lrd模式 //先序遍历dlr
void preordertraverse(btnode<t> *p) //p为二叉树的根节点,以下同是
{
if (p != null)
{
this->visit(p);
this->preordertraverse(p->lchild);
this->preordertraverse(p->rchild);
}
}
//中序遍历ldr
void inordertraverse(btnode<t> *p)
{
if (p != null)
{
this->inordertraverse(p->lchild);
this->visit(p);
this->inordertraverse(p->rchild);
}
}
//后序遍历lrd
void postordertraverse(btnode<t> *p)
{
if (p != null)
{
this->postordertraverse(p->lchild);
this->postordertraverse(p->rchild);
this->visit();
}
}
//统计叶子结点的数目
int getnumofleaf(btnode<t> *p)
{
int number = 0;
if (p == null)
number = 0;
else if (p->lchild == null && p->rchild == null)
number = 1;
else
number = this->getnumofleaf(p->lchild) + this->getnumofleaf(p->rchild);
return number;
}
//计算二叉树的高度
int getheight(btnode<t> *p)
{
int height = 0;
if (p == null)
height = 0;
else if (p->lchild == null && p->rchild == null)
height = 1;
else
{
int lheight = this->getheight(p->lchild) + 1;
int rheight = this->getheight(p->rchild) + 1;
height = lheight > rheight ? lheight : rheight;
}
return height;
}
原理:
为了节省资源空间,将空闲的指针域给利用起来,将此指针域设为该结点的前驱或后继指针
ltag和rtag。如果ltag=0或rtag=0则表明该结点的左或右孩子存在;否则,指向前驱或后继指针。 实现:
bintree,先序,中序,后序都可if(bintree!=null)
{
inordertraverse(bintree->lchild);
dosomething;
inordertraverse(bintree->rchild);
}
bintree->ltag=0; 否则bintree->ltag=1;bintree->lchild=pre;(pre为当前结点的前驱结点,就是遍历的上一个结点)
3. 判断前驱结点pre的右孩子是否存在,若存在则让bintree->rtag=0;
否则pre->rtag=1;pre->rchild=bintree;
4. 令前驱结点pre始终保持在当前结点的上一个结点,即:pre=bintree;
代码实现:
if(bintree->lchild==null)
{
bintree->ltag=1;
bintree->lchild=pre;
}
if(pre!=null&&pre->rchild==null)
{
pre->rtag=1;
pre->rchild=bintree;
}
pre=bintree;
中序线索二叉树查找某个结点p的前驱结点pre
ldr可知,结点p的前驱结点应是p的左子树;p->ltag=1;则该结点的前驱为pre=p->lchild;p->ltag=0; 根据中序遍历的定义可知,结点p的前驱结点应是p的左子树的“最下右孩子”;
用代码可表示为:
q=p->lchild;
while(q->rtag==0)
{
q=q->rchild;
}
pre=q;
中序线索二叉树查找某个结点p的后继结点next,方法原理同上。
中序线索二叉树的插入和删除操作
插入操作:
向二叉树中结点p的右孩子插入结点r,即p->rchild=r;
1. 首先遍历二叉树,找到结点p
p的右孩子不存在,即p->rtag=1;p的后继变为r,r的后继变为p原来的后继p->rchild,r的前驱为pr->ltag=1;r->lchild=p;r->rtag=1;r->rchild=p->rchild;p->rchild=r;注意顺序不能变p的右孩子存在,即p->rtag=0;r变为p结点的右孩子,原来p的右孩子变为r的右孩子p的后继将变为r,p为r的前驱r的后继变为右子树“最下端左孩子” 代码实现:
if(p->rtag==1)
{
btnode<t> *r=new btnode<t>(data:data,ltag:1,rtag:1,lchild:p,rchild:p->rchild);
p->rchild=r;
p->rtag=0;
}
else
{
btnode<t> *r=new btnode<t>(data:data,ltag:1,rtag:0,lchild:p,rchild:p->rchild);
p->rchild=r;
btnode<t> *q=r->rchild;
while(q->ltag==0)
{
q=q->lchild;
}
q->lchild=r;
}
删除操作和插入操作类似相同,方法和原理同上。
哈夫曼树是指带权路径最小的二叉树。
给定一定的带权叶子结点,构造哈夫曼树:
1. 在这些结点中寻找两个权最小的叶子结点,这两个结点与\(n_1\)结点组成一棵树,\(n_1\)结点的权变为两个结点的和;
2. 将\(n_1\)结点和其它叶子结点放在一起,在其中找到两个权最小的树,组成一棵新树;
3. 注意在组成新树时,将权相对较小的值作为左孩子;
4. 以此类推,重复上述的步骤,最终将得到哈夫曼树。
根据以上的构造可以得到,哈夫曼树只有度为2的结点和叶子结点,故当哈夫曼树有n个叶子结点时,其总结点数为2n-1。
哈夫曼树存储结构:
| weight | parent | lchild | rchild |
权重 双亲 左孩子 右孩子
叶子结点的左孩子和右孩子均为空。
哈夫曼树的应用:
哈夫曼编码:前缀编码,前缀编码容易区分,不易相重;缩短编码长度,便于传输 常用于压缩文件编码
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复
如何在没有core文件的情况下用dmesg+addr2line定位段错误
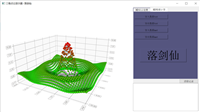
用QT制作3D点云显示器——QtDataVisualization
网友评论