早川濑里奈全集,花样年华赵彤微博,突袭2:暴徒
一、预备知识—程序的内存分配
一个由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其
操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回
收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的
全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另
一块区域。 - 程序结束后由系统释放。
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
二、Java把内存分成两种,一种叫做栈内存,一种叫做堆内存
在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
堆内存用于存放由new创建的对象和数组。在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组&对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
java中内存分配策略及堆和栈的比较
堆是应用程序在运行的时候请求操作系统分配给自己内存,由于从操作系统管理的内存分配,所以在分配和销毁时都要占用时间,因此用堆的效率非常低.但是堆的优点在于,编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间,因此,用堆保存数据时会得到更大的灵活性。事实上,面向对象的多态性,堆内存分配是必不可少的,因为多态变量所需的存储空间只有在运行时创建了对象之后才能确定.在C++中,要求创建一个对象时,只需用 new命令编制相关的代码即可。执行这些代码时,会在堆里自动进行数据的保存.当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花掉更长的时间!这也正是导致我们刚才所说的效率低的原因,看来列宁同志说的好,人的优点往往也是人的缺点,人的缺点往往
《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》
在中文版的一书中译作“值栈”。其本身数据结构是一个栈,使用者可以把一些对象(又称作bean)存入值栈中,然后使用动态的表达式来读取bean的属性,或者对bean进行一些其他操作。由于值栈中可能有多个bean,值栈会按bean出栈的顺序依次尝试使用动态的表达式来读取值,直到成功读取值为止。在Struts2中,默认的值栈实现是,即默认使用Ognl这个动态表达式语言来读取值。
在Struts2执行一次请求的过程中,Struts2会把当前的Action对象自动放入值栈。这样,在渲染JSP时,JSP里的代码使用
在自定义的拦截器中,使用.getStack()方法( ActionInvocation 是拦截器的方法参数)。
在Action类中,让拦截器注入ValueStack或者使用.getContext().getValueStack()来值栈(ActionContext.getContext()为静态方法)。注意:ActionContext分配context的方式是基于线程的,如果使用这种方法,请确保它不会出错。
在JSP中,直接使用标签即可获得值栈里的数据,而一般不用获取值栈本身。
如何将对象存入值栈:Struts2自动存入Action:之前已经提到,Struts2在执行一次请求的过程中会把当前的Action对象自动存入值栈中。
会存入Action的model属性:如果你使用了Struts2提供的 ModelDrivenInterceptor,则它会把Action对象的getModel()方法得到的对象存入值栈中。此时,值栈最底层为Action类,其次为这个model。
在自定义的拦截器中存入值栈:得到值栈对象后调用ValueStack.put(Object object)方法。
在Action类中存入值栈:得到值栈对象后调用ValueStack.put(Object object)方法。
在JSP中存入值栈:标签是专门用来在JSP中把指定的value放入值栈的,但value被放入值栈的时间仅在s:push标签内,即程序运行到标签处会把value从值栈中移出。另外,还有一些标签比如由于其功能的需要也会把一些对象放到值栈中。
让值栈执行表达式来获得值:在自定义的拦截器中,获得值栈后,使用ValueStack.findValue(...)等方法。
在Action类中,获得值栈后,使用ValueStack.findVlaue(...)等方法。
在JSP中,一些标签的属性是直接在值栈上执行Ognl表达式的,比如的value属性。如果标签的属性不是直接执行Ognl表达式的,则需要使用“%{}”将表达式括起来,这样Struts2就会以Ognl表达式来执行了。至于到底哪些标签是直接执行Ognl而哪些不是,请参考。
在JSP中跳过栈顶元素直接访问第二层:在JSP中,使用[0]、[1]等表达式来指定从栈的第几层开始执行表达式。[0]表示从栈顶开始,[1]表示从栈的第二层开始。比如表达式“name”等价于“[0].name”。
《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》《》
在JSP中访问值栈对象本身(而不是它们的属性)在表示式中使用top关键字来访问对象本身。比如,表达式“name”等价于“top.name”,表达式“[0].top”等价于“top”,表达式“[1].top.name”等价于“[1].name”。
总之,值栈主要目的是为了让JSP内能方便的访问Action的属性。
通过对struts2的一段时间的接触,将自己对OGNL的核心值栈说说,值栈:简单的说,就是存放action的堆栈,当我们提交一个请求道服务器端 action时,就有个堆栈,如果action在服务器端进行跳转,所有action共用一个堆栈,当需要保存在action中的数据时,首先从栈顶开始 搜索,若找到相同的属性名(与要获得的数据的属性名相同)时,即将值取出,但这种情况可能出现找到的值不是我们想要的值,那么解决此问题需要用TOP语法 和N语法来进行解决。
当在客服端进行跳转时,当有请求提交到服务器的action时,只有一个堆栈存在,堆栈中存放的是当前的请求的action,而原来那么则销毁了(本人观 点,感觉如同request请求一样)。
******************************************************
众所周知,Strut 2的Action类通过属性可以获得所有相关的值,如请求参数、Action配置参数、向其他Action传递属性值(通过chain结果)等等。要获得 这些参数值,我们要做的唯一一件事就是在Action类中声明与参数同名的属性,在Struts 2调用Action类的Action方法(默认是execute方法)之前,就会为相应的Action属性赋值。
要完成这个功能,有很大程度上,Struts 2要依赖于ValueStack对象。这个对象贯穿整个Action的生命周期(每个Action类的对象实例会拥有一个ValueStack对象)。当 Struts 2接收到一个.action的请求后,会先建立Action类的对象实例,但并不会调用Action方法,而是先将Action类的相应属性放到 ValueStack对象的顶层节点(ValueStack对象相当于一个栈)。只是所有的属性值都是默认的值,如String类型的属性值为 null,int类型的属性值为0等。
在处理完上述工作后,Struts 2就会调用拦截器链中的拦截器,当调用完所有的拦截器后,最后会调用Action类的Action方法,在调用Action方法之前,会将 ValueStack对象顶层节点中的属性值赋给Action类中相应的属性。大家要注意,在这里就给我们带来了很大的灵活性。也就是说,在Struts 2调用拦截器的过程中,可以改变ValueStack对象中属性的值,当改变某个属性值后,Action类的相应属性值就会变成在拦截器中最后改变该属性 的这个值。
从上面的描述很容易知道,在Struts 2的的Action类可以获得与属性同名的参数值就是通过不同的拦截器来处理的,如获得请求参数的拦截器是params,获得Action的配置参数的拦 截器是staticParams等。在这些拦截器内部读取相应的值,并更新ValueStack对象顶层节点的相应属性的值。而ValueStack对象 就象一个传送带,将属性值从一个拦截器传到了另一个拦截器(当然,在这其间,属性值可能改变),最后会传到Action对象,并将ValueStack对 象中的属性的值终值赋给Action类的相应属性
众所周知,Strut 2的Action类通过属性可以获得所有相关的值,如请求参数、Action配置参数、向其他Action传递属性值(通过chain结果)等等。要获得 这些参数值,我们要做的唯一一件事就是在Action类中声明与参数同名的属性,在Struts 2调用Action类的Action方法(默认是execute方法)之前,就会为相应的Action属性赋值。
要完成这个功能,有很大程度上,Struts 2要依赖于ValueStack对象。这个对象贯穿整个Action的生命周期(每个Action类的对象实例会拥有一个ValueStack对象)。当 Struts 2接收到一个.action的请求后,会先建立Action类的对象实例,但并不会调用Action方法,而是先将Action类的相应属性放到 ValueStack对象的顶层节点(ValueStack对象相当于一个栈)。只是所有的属性值都是默认的值,如String类型的属性值为 null,int类型的属性值为0等。
在处理完上述工作后,Struts 2就会调用拦截器链中的拦截器,当调用完所有的拦截器后,最后会调用Action类的Action方法,在调用Action方法之前,会将 ValueStack对象顶层节点中的属性值赋给Action类中相应的属性。大家要注意,在这里就给我们带来了很大的灵活性。也就是说,在Struts 2调用拦截器的过程中,可以改变ValueStack对象中属性的值,当改变某个属性值后,Action类的相应属性值就会变成在拦截器中最后改变该属性 的这个值。
从上面的描述很容易知道,在Struts 2的的Action类可以获得与属性同名的参数值就是通过不同的拦截器来处理的,如获得请求参数的拦截器是params,获得Action的配置参数的拦 截器是staticParams等。在这些拦截器内部读取相应的值,并更新ValueStack对象顶层节点的相应属性的值。而ValueStack对象 就象一个传送带,将属性值从一个拦截器传到了另一个拦截器(当然,在这其间,属性值可能改变),最后会传到Action对象,并将ValueStack对 象中的属性的值终值赋给Action类的相应属性
如对本文有疑问,请在下面进行留言讨论,广大热心网友会与你互动!! 点击进行留言回复
如何在没有core文件的情况下用dmesg+addr2line定位段错误
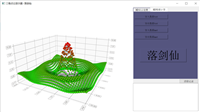
用QT制作3D点云显示器——QtDataVisualization
网友评论